How to run for inference Llama-3_1-Nemotron-51B-Instruct?


The large language model (LLM) Llama-3_1-Nemotron-51B-Instruct provides an excellent balance between model efficiency and correctness. This model was created by NVIDIA employing a revolutionary Neural Architecture Search (NAS) technique that significantly lowers the model's memory footprint, allowing for higher workloads and model fitting on a single GPU at high workloads. This makes it possible to choose a preferred point in the accuracy-efficiency tradeoff. 40 billion tokens of data centered on English single-turn and multi-turn chat use cases were used to refine the model.
Neural Architecture Search (NAS) and knowledge distillation are powerfully combined in the Llama-3.1-Nemotron-51B. These methods greatly lower computational costs while preserving the model's excellent accuracy. Let's examine how these technologies work together in more detail:
- Neural Architecture Search (NAS): Typically, the same blocks are used throughout the architecture to build large language models (LLMs). Design is made simpler, but inefficiencies are also introduced. These blocks are optimized by NVIDIA's NAS technique, which deliberately eliminates superfluous elements like feed-forward networks (FFNs) and attention mechanisms to produce an architecture designed for effective inference on the H100 GPU.
- Training a smaller "student" model (Nemotron-51B) to replicate the actions of a larger "teacher" model (Llama-3.1-70B) is known as knowledge distillation. This method enables NVIDIA to handle heavy workloads while retaining a high degree of accuracy by drastically reducing the model's size without compromising performance.
| Accuracy | Efficiency | |||
| MT Bench | MMLU | Text generation (128/1024) | Summarization/ RAG (2048/128) | |
| Llama-3.1- Nemotron-51B- Instruct | 8.99 | 80.2% | 6472 | 653 |
| Llama 3.1-70B- Instruct | 8.93 | 81.66% | 2975 | 339 |
| Llama 3.1-70B- Instruct (single GPU) | — | — | 1274 | 301 |
| Llama 3-70B | 8.94 | 80.17% | 2975 | 339 |
Overview of the Llama-3.1-Nemotron-51B-Instruct accuracy and efficiency.
| Benchmark | Llama-3.1 70B-instruct | Llama-3.1-Nemotron-51B- Instruct | Accuracy preserved |
| winogrande | 85.08% | 84.53% | 99.35% |
| arc_challenge | 70.39% | 69.20% | 98.30% |
| MMLU | 81.66% | 80.20% | 98.21% |
| hellaswag | 86.44% | 85.58% | 99.01% |
| gsm8k | 92.04% | 91.43% | 99.34% |
| truthfulqa | 59.86% | 58.63% | 97.94% |
| xlsum_english | 33.86% | 31.61% | 93.36% |
| MMLU Chat | 81.76% | 80.58% | 98.55% |
| gsm8k Chat | 81.58% | 81.88% | 100.37% |
| Instruct HumanEval (n=20) | 75.85% | 73.84% | 97.35% |
| MT Bench | 8.93 | 8.99 | 100.67% |
Accuracy comparison of the Nemotron model to the Llama-3.1-70B-Instruct model across several industry benchmarks
Step-by-Step Process to deploy Llama-3_1-Nemotron-51B-Instruct in the Cloud
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meet GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you've signed up, log into your account.
Follow the account setup process and provide the necessary details and information.
Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift's GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.
Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deployment.
Step 3: Select a Model, Region, and Storage
In the "GPU Nodes" tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.
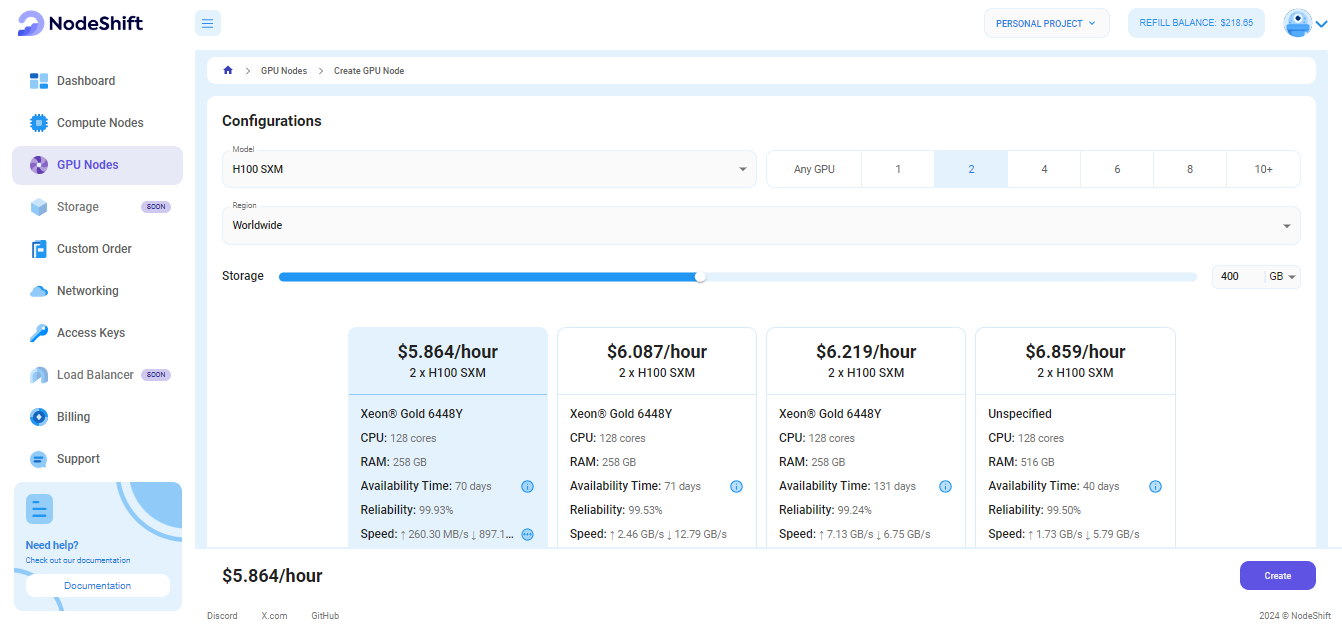
We will use 2x H100 SXM GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy the Llama-3_1-Nemotron-51B-Instruct Model on a Jupyter Virtual Machine. This open-source platform will allow you to install and run the Llama-3_1-Nemotron-51B-Instruct Model on your GPU node. By running this model on a Jupyter Notebook, we avoid using the terminal, simplifying the process and reducing the setup time. This allows you to configure the model in just a few steps and minutes.
Note: NodeShift provides multiple image template options, such as TensorFlow, PyTorch, NVIDIA CUDA, Deepo, Whisper ASR Webservice, and Jupyter Notebook. With these options, you don’t need to install additional libraries or packages to run Jupyter Notebook. You can start Jupyter Notebook in just a few simple clicks.
After choosing the image, click the 'Create' button, and your Virtual Machine will be deployed.
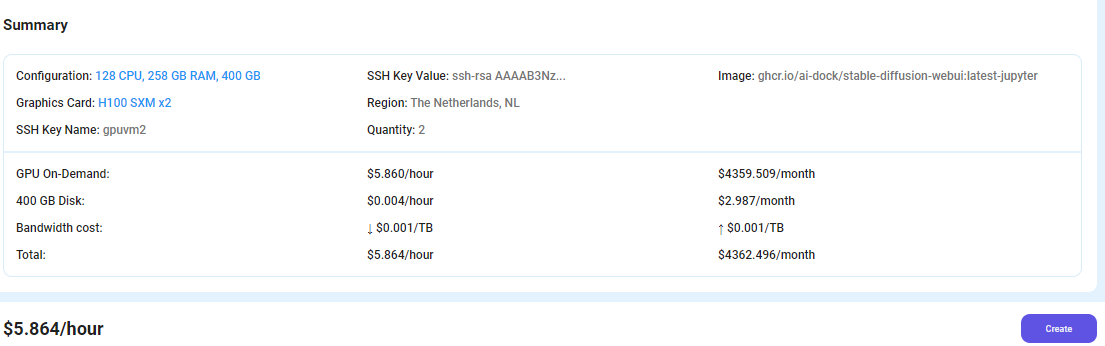
Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.
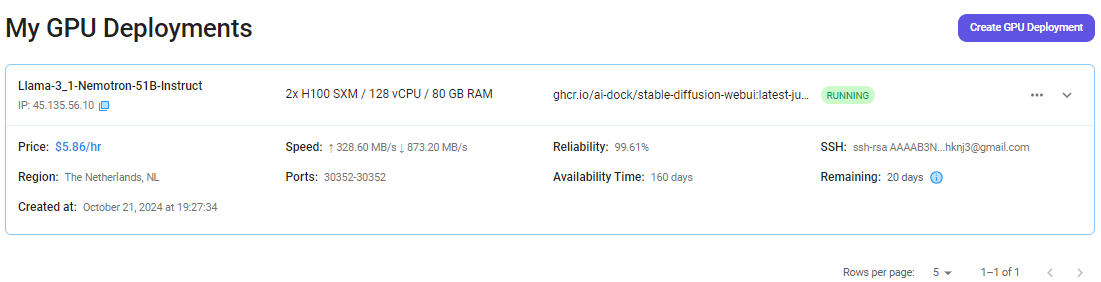
Step 7: Connect to Jupyter Notebook
Once your GPU Virtual Machine deployment is successfully created and has reached the 'RUNNING' status, you can navigate to the page of your GPU Deployment Instance. Then, click the 'Connect' Button in the top right corner.
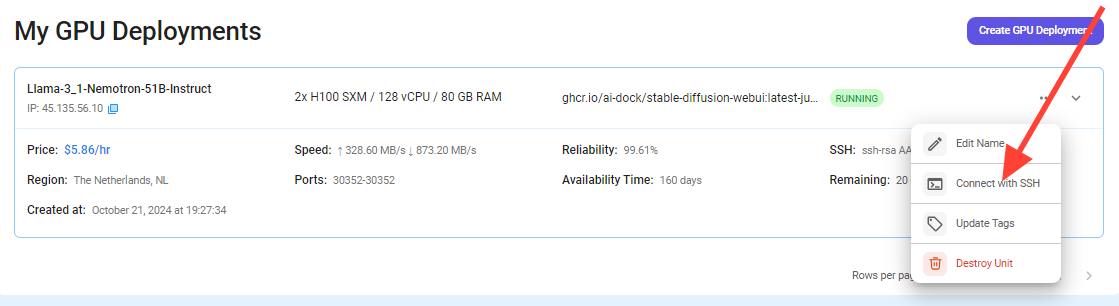
After clicking the 'Connect' button, you can view the Jupyter Notebook.
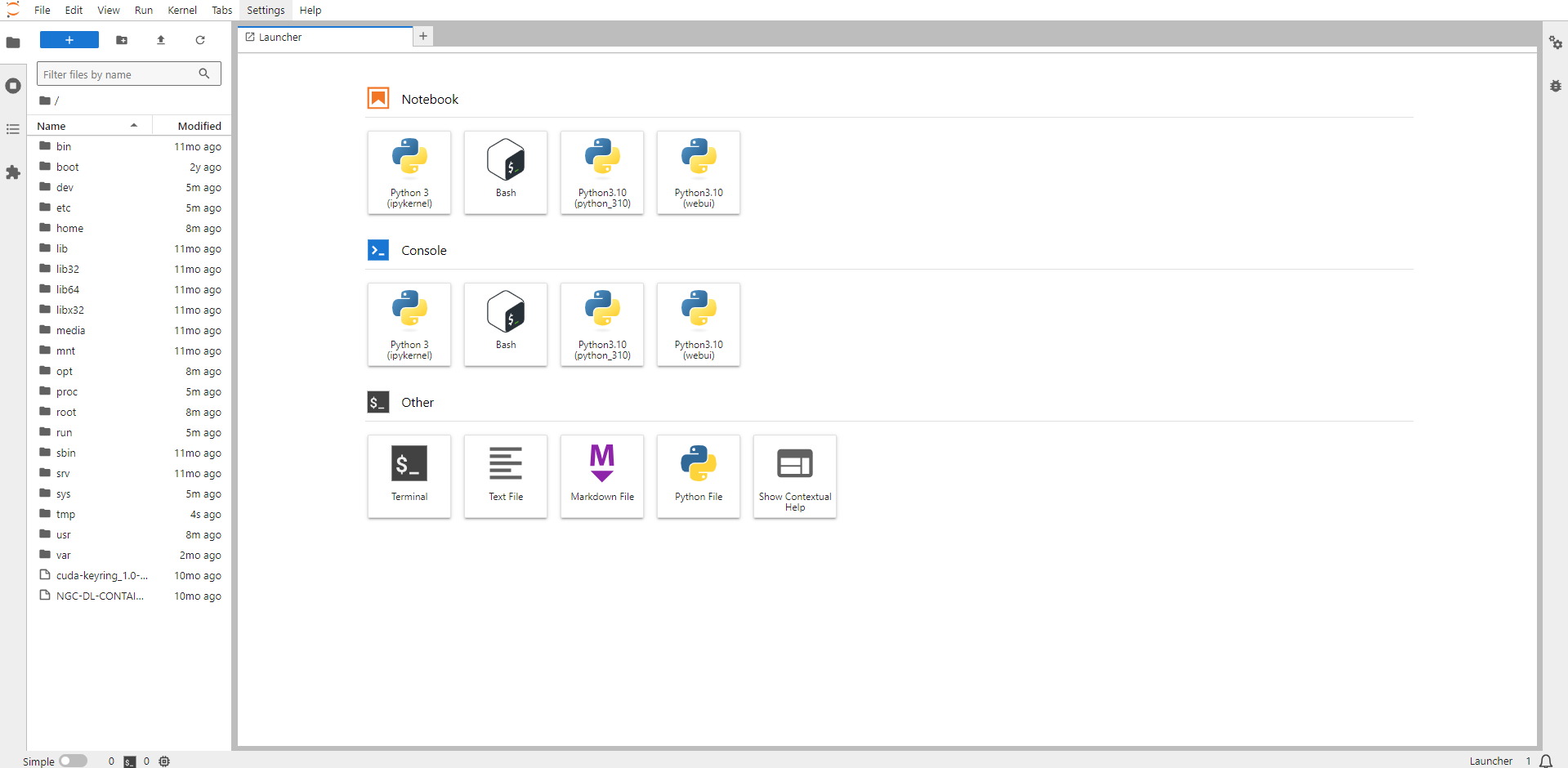
Now open Python 3(pykernel) Notebook.
Next, If you want to check the GPU details, run the command in the Jupyter Notebook cell:
!nvidia-smi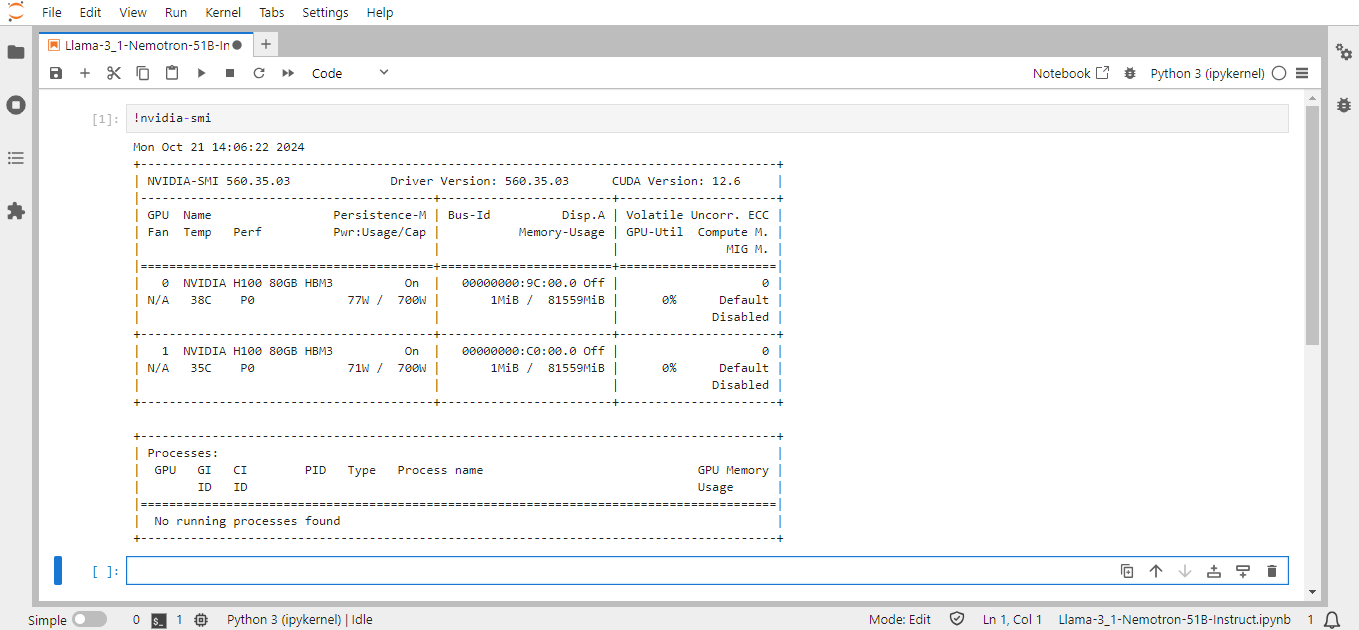
Step 8: Install the Required Packages and Libraries
Run the following command in the Jupyter Notebook cell to install the required Packages and Libraries:
!pip install torch==2.4.0 transformers==4.44.0 accelerate
Transformers: Transformers provide APIs and tools to download and efficiently train pre-trained models.
Torch: Torch is an open-source machine learning library, a scientific computing framework, and a scripting language based on Lua. It provides LuaJIT interfaces to deep learning algorithms implemented in C. Torch was designed with performance in mind, leveraging highly optimized libraries like CUDA, BLAS, and LAPACK for numerical computations.
Accelerate: Accelerate is a library that enables the same PyTorch code to be run across any distributed configuration by adding just four lines of code.
Step 9: Load and Run the Model in Jupyter Notebook
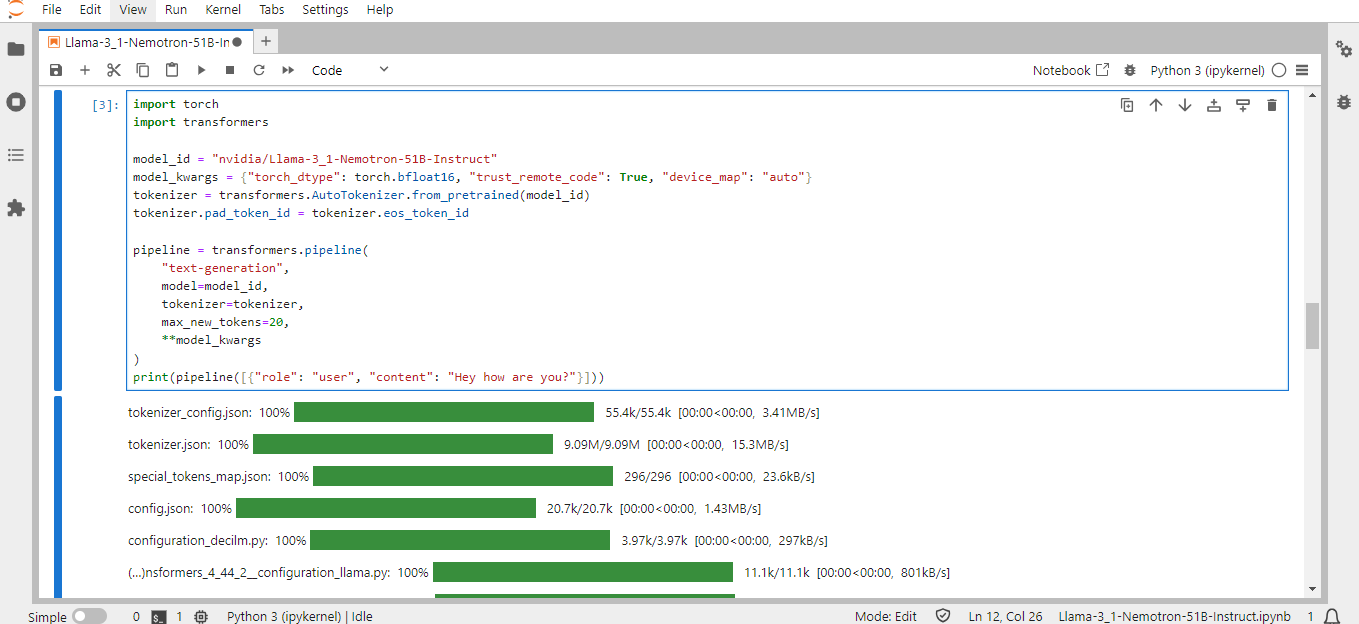
Run the following model code in the Jupyter Notebook to load and run the model:
import torch
import transformers
model_id = "nvidia/Llama-3_1-Nemotron-51B-Instruct"
model_kwargs = {"torch_dtype": torch.bfloat16, "trust_remote_code": True, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=20,
**model_kwargs
)
print(pipeline([{"role": "user", "content": "Hey how are you?"}]))
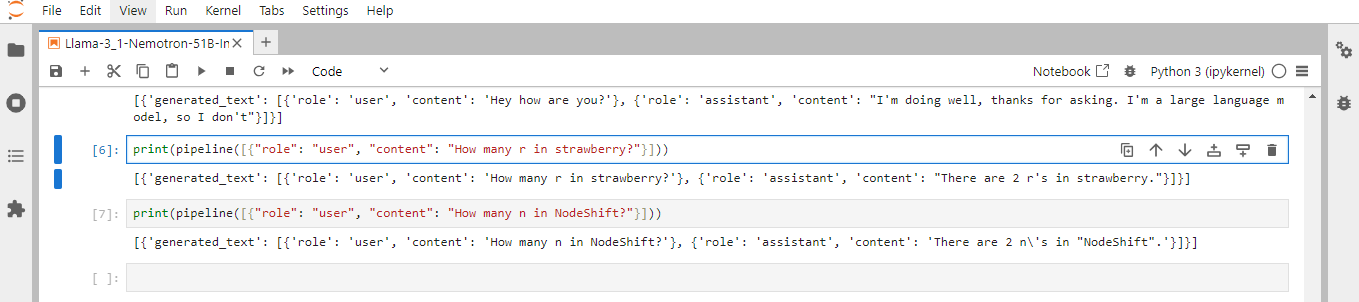
Step 10: Generate Responses in Jupyter Notebook
Print Output in Jupyter Notebook:
Conclusion
Llama-3_1-Nemotron-51B-Instruct is a groundbreaking open-source model from NVIDIA that brings state-of-the-art AI capabilities to developers and researchers. Following this step-by-step guide, you can quickly deploy Llama-3_1-Nemotron-51B-Instruct on a GPU-powered Virtual Machine with NodeShift, harnessing its full potential. NodeShift provides an accessible, secure, affordable platform to run your AI models efficiently. It is an excellent choice for those experimenting with Llama-3_1-Nemotron-51B-Instruct and other cutting-edge AI tools.



