How to Run Gemma2 9b in the Cloud?


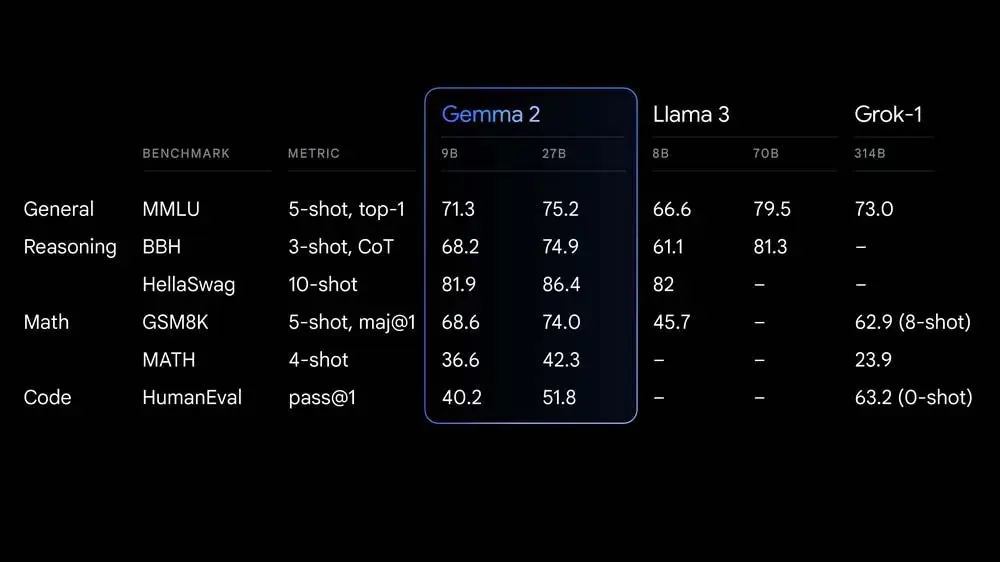
Gemma 2 is Google's latest iteration of open LLMs. It comes in two sizes, 9 billion and 27 billion parameters, with base (pre-trained) and instruction-tuned versions. Gemma is based on Google Deepmind Gemini and has a context length of 8K tokens:
- gemma-2-9b: Base 9B model.
- gemma-2-9b-it: Instruction fine-tuned version of the base 9B model.
- gemma-2-27b: Base 27B model.
- gemma-2-27b-it: Instruction fine-tuned version of the base 27B model.
The 9B model was trained on approximately 8 trillion tokens, while the 27B version was trained on about 13 trillion tokens of web data, code, and math.
Both models feature a context length of 8,000 tokens. The instruction-tuned variants are denoted as “gemma-2–9b-it” and “gemma-2–27b-it,” while the base models are “gemma-2–9b” and “gemma-2–27b”.
These lightweight models are designed to run efficiently on various hardware, including Nvidia GPUs and Google’s TPUs, making them suitable for cloud and on-device applications.
Gemma 2 has many similarities with the first iteration. It has a context length of 8192 tokens and uses Rotary Position Embedding (RoPE). There are four main advances in Gemma 2 compared to the original Gemma:
- Sliding window attention: Interleave sliding window and full-quadratic attention for quality generation.
- Logit soft-capping: Prevents logits from growing excessively by scaling them to a fixed range, improving training.
- Knowledge Distillation: Leverage a larger teacher model to train a smaller model (for the 9B model).
- Model Merging: Combines two or more LLMs into a single new model
Gemma 2 was trained on Google Cloud TPU (27B on v5p, 9B on TPU v4) using JAX and ML Pathways. Gemma 2 Instruct has been optimized for dialogue applications and trained on a mix of synthetic and human-generated prompt-response pairs using Supervised Fine-Tuning (SFT), Distillation from a larger model, Reinforcement Learning from Human Feedback (RLHF) using a reward model oriented more towards conversational capabilities, and model merging using WARP to improve overall performance.
In this blog, you'll learn:
- About Gemma2 9B
- Setup GPU-powered Virtual Machine offered by NodeShift
- Run Gemma2 9B in the NodeShift Cloud.
Step-by-Step Process to Run Gemma2 9b in the Cloud
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meets GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you've signed up, log into your account.
Follow the account setup process and provide the necessary details and information.
Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift's GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.
Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deployment.
Step 3: Select a Model, Region, and Storage
In the "GPU Nodes" tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.
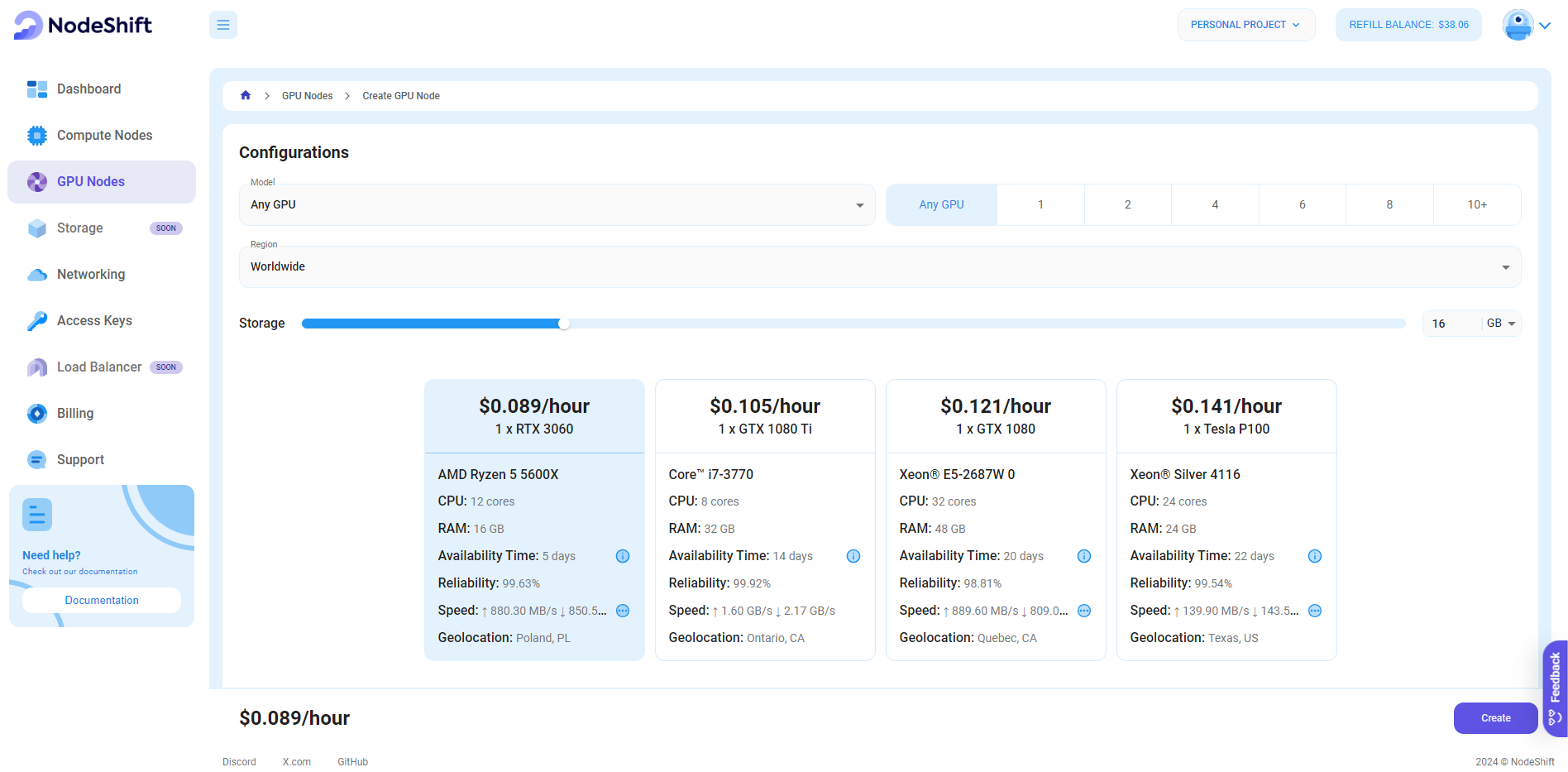
We will use 1x RTX A6000 GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy Gemma2 9B on an NVIDIA Cuda Virtual Machine. This proprietary, closed-source parallel computing platform will allow you to install Gemma 7B on your GPU Node.
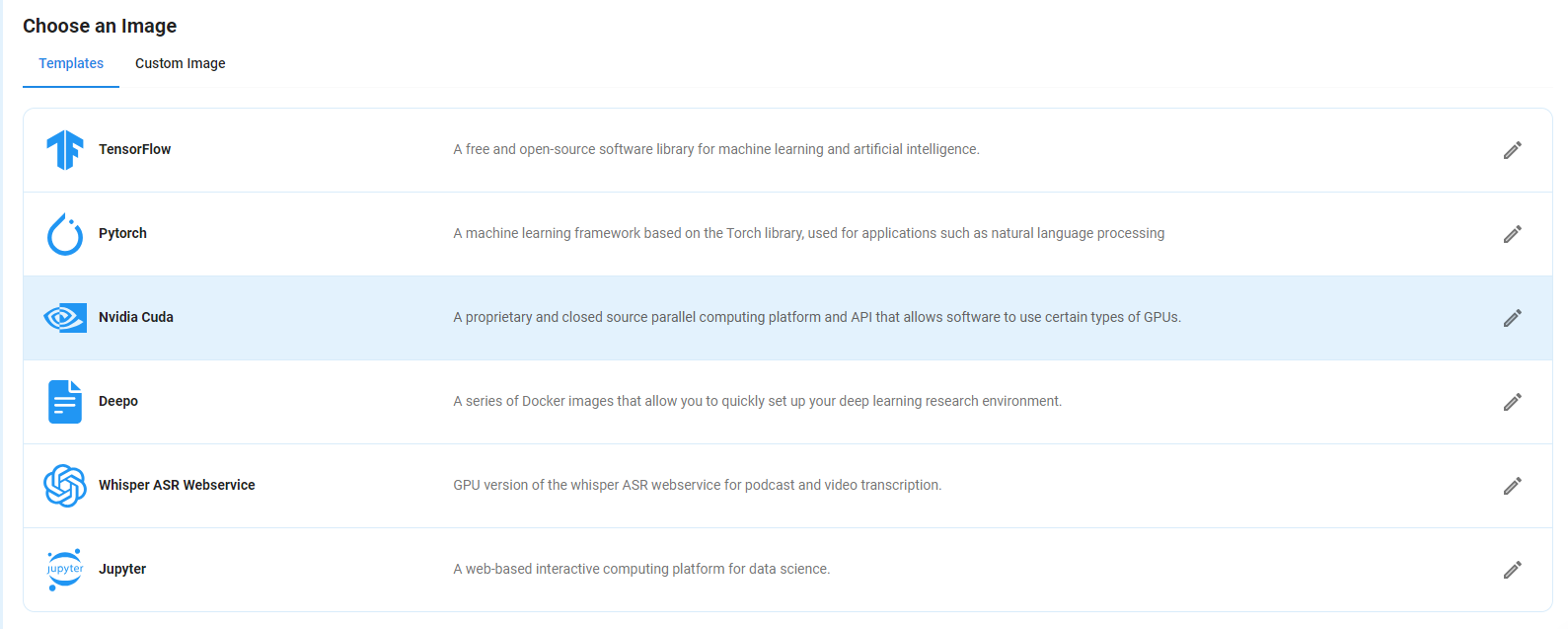
After choosing the image, click the 'Create' button, and your Virtual Machine will be deployed.
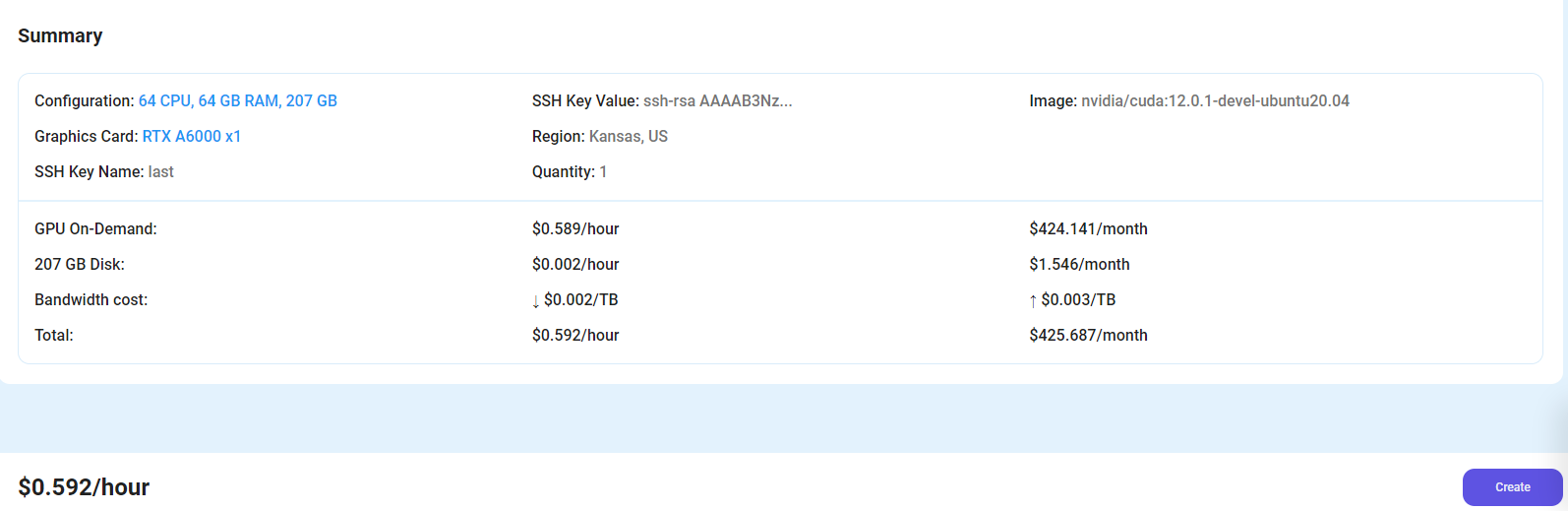
Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.
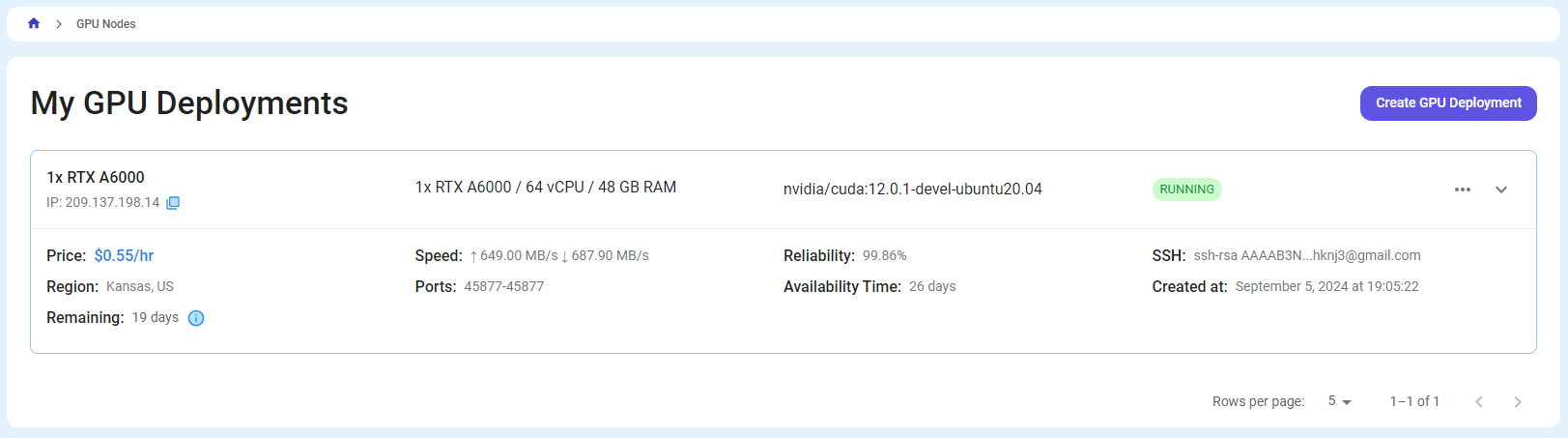
Step 7: Connect to GPUs using SSH
NodeShift GPUs can be connected to and controlled through a terminal using the SSH key provided during GPU creation.
Once your GPU Node deployment is successfully created and has reached the 'RUNNING' status, you can navigate to the page of your GPU Deployment Instance. Then, click the 'Connect' button in the top right corner.
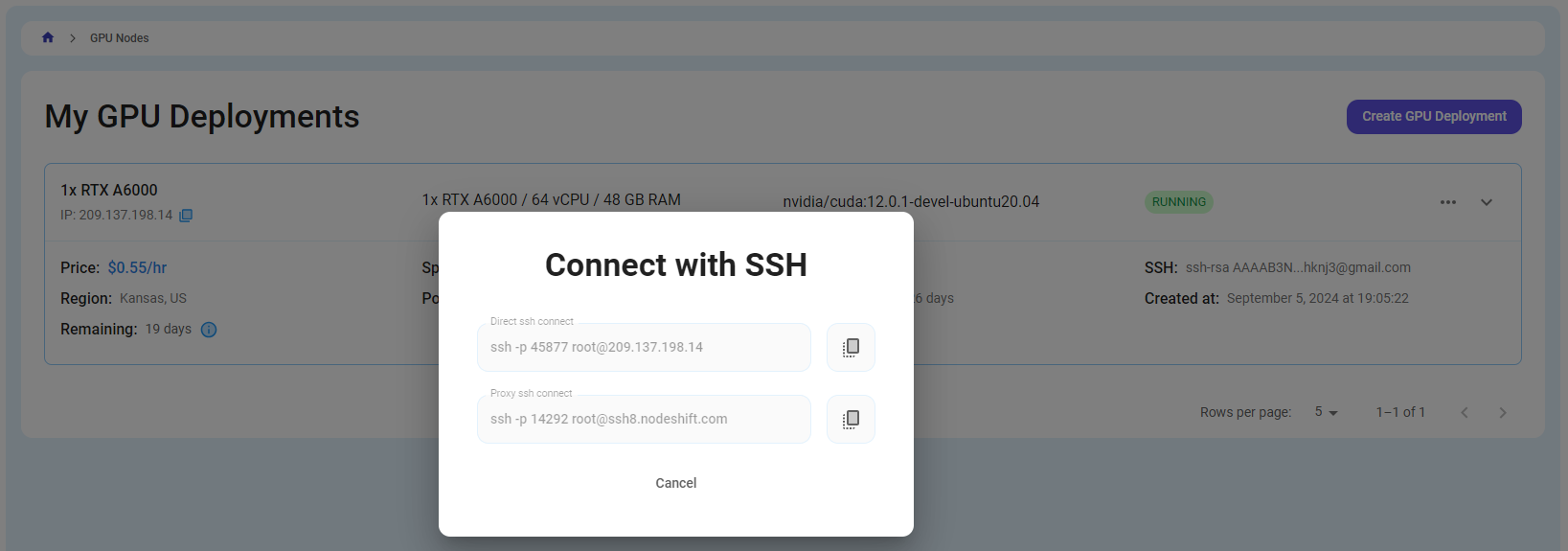
Now open your terminal and paste the proxy SSH IP or direct SSH IP.
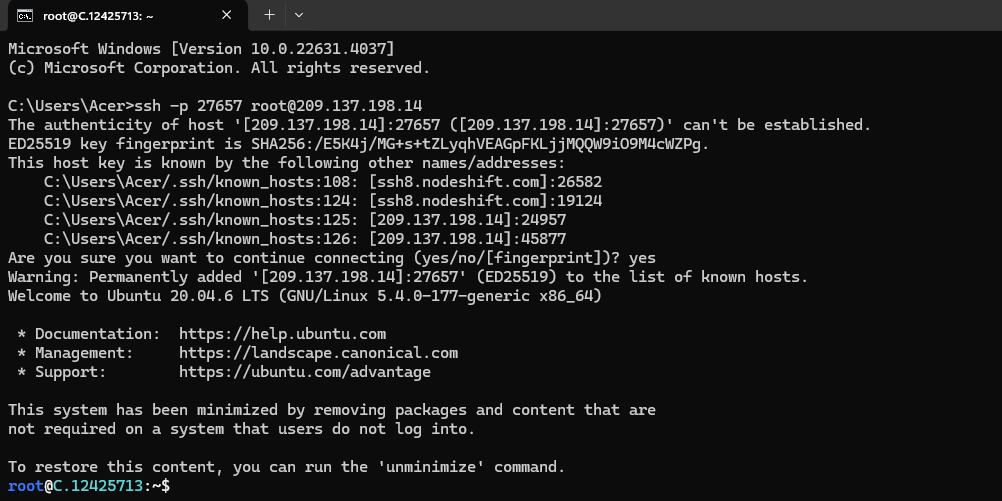
Next, If you want to check the GPU details, run the command below:
nvidia-smi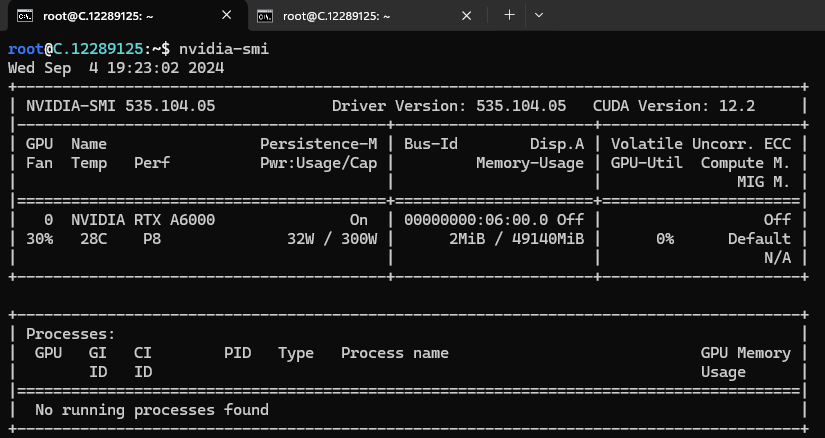
Step 8: Install Google-Gemma2 9B
After completing the steps above, it's time to download Gemma2 from the Ollama website.
Website Link:https://ollama.com/library/gemma2:9b
We will be running Google-Gemma2 9B. Select the 9B model from the website.
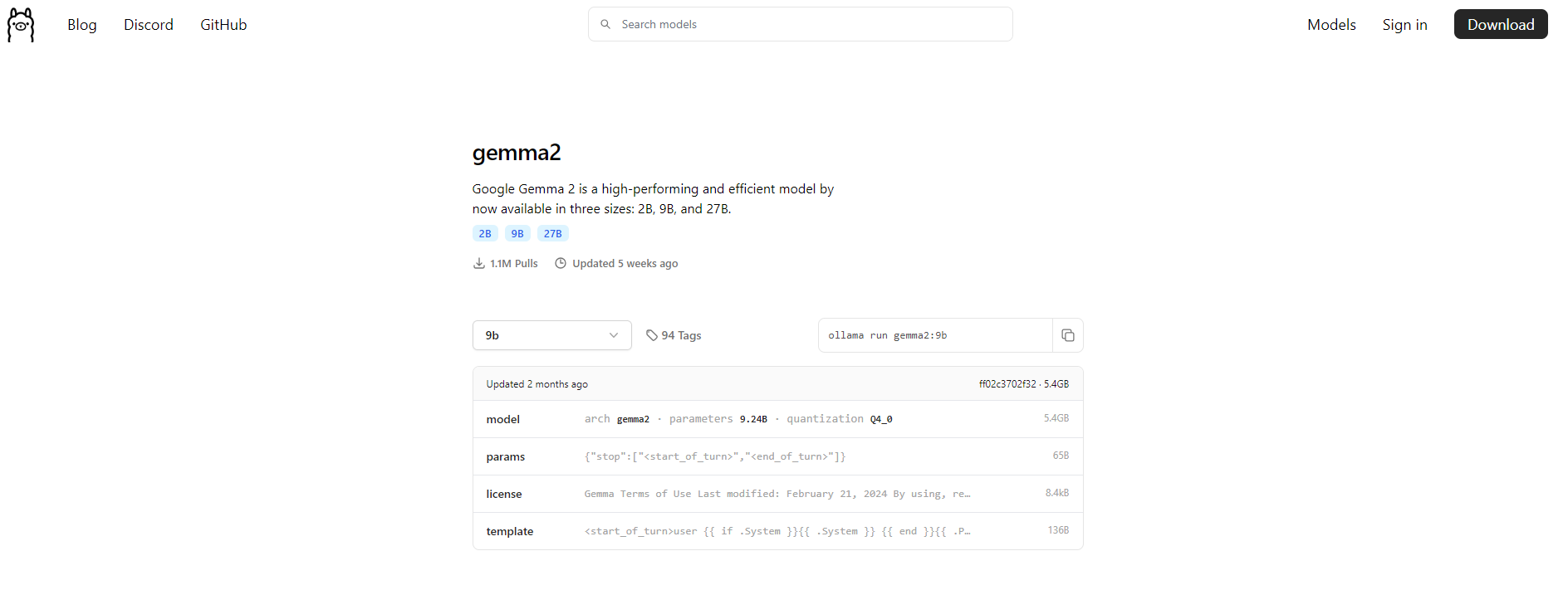
Then run the following command to install the Ollama:
curl -fsSL https://ollama.com/install.sh | sh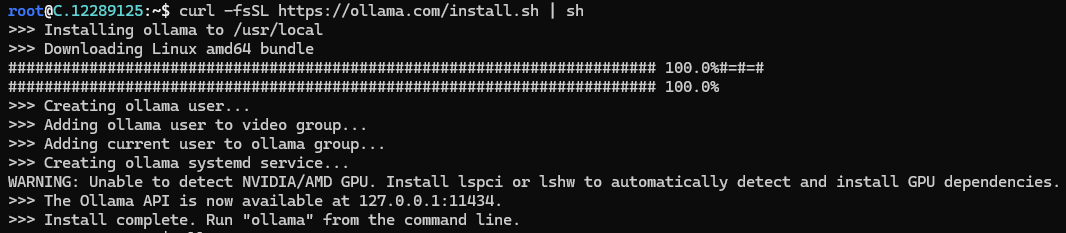
After the installation process is complete, run the following command to see a list of available commands:
ollama
Next, Run the following command to host the Gemma model to be accessed and utilized efficiently.
ollama serve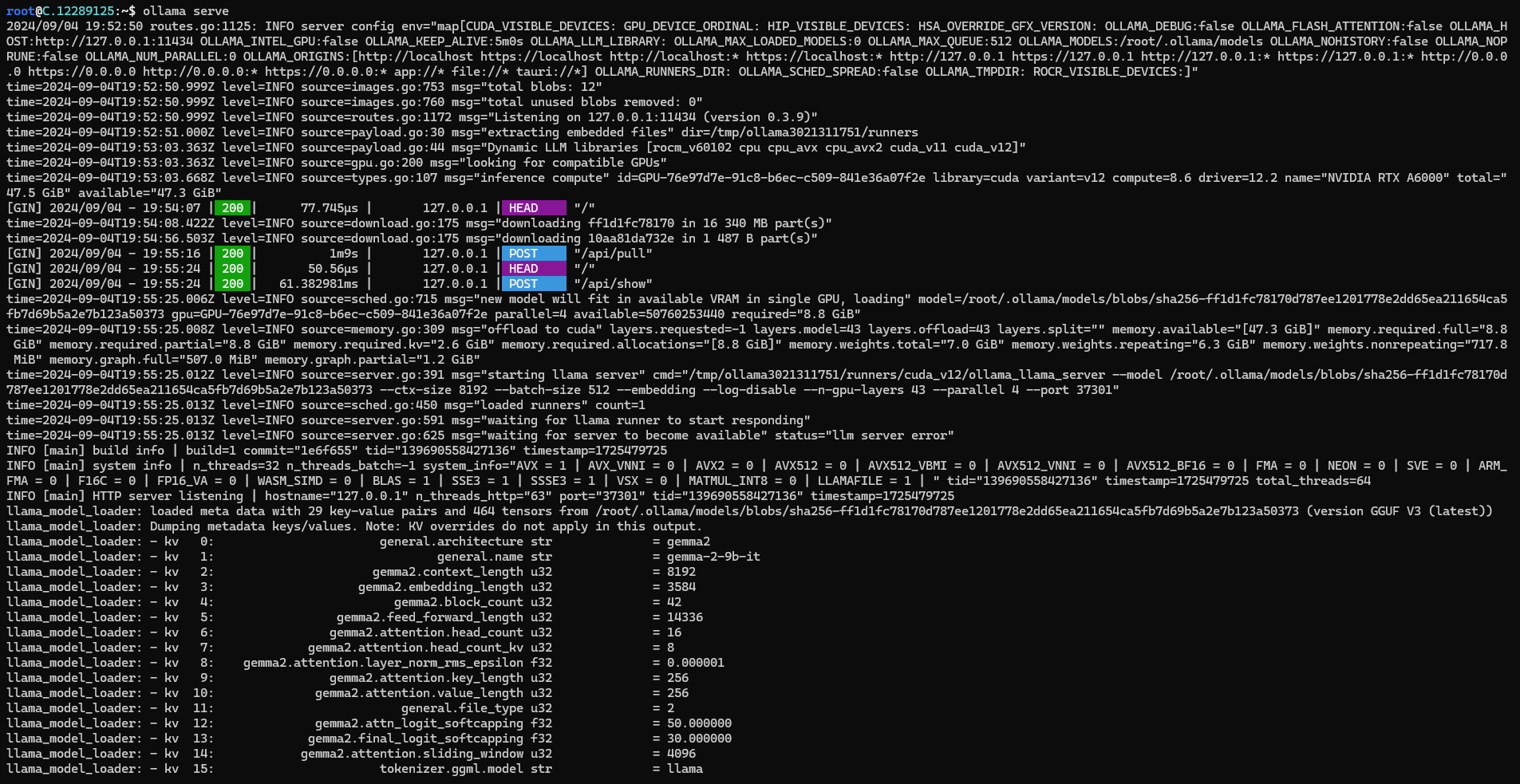
Step 9: Install Google-Gemma2 9B Model
To install the Google-Gemma2 9B Model, run the following command:
ollama pull gemma2:9b
Step 10: Run Google-Gemma2 9B Model
Now, you can run the model in the terminal using the following command and interact with your model:
ollama run gemma2:9b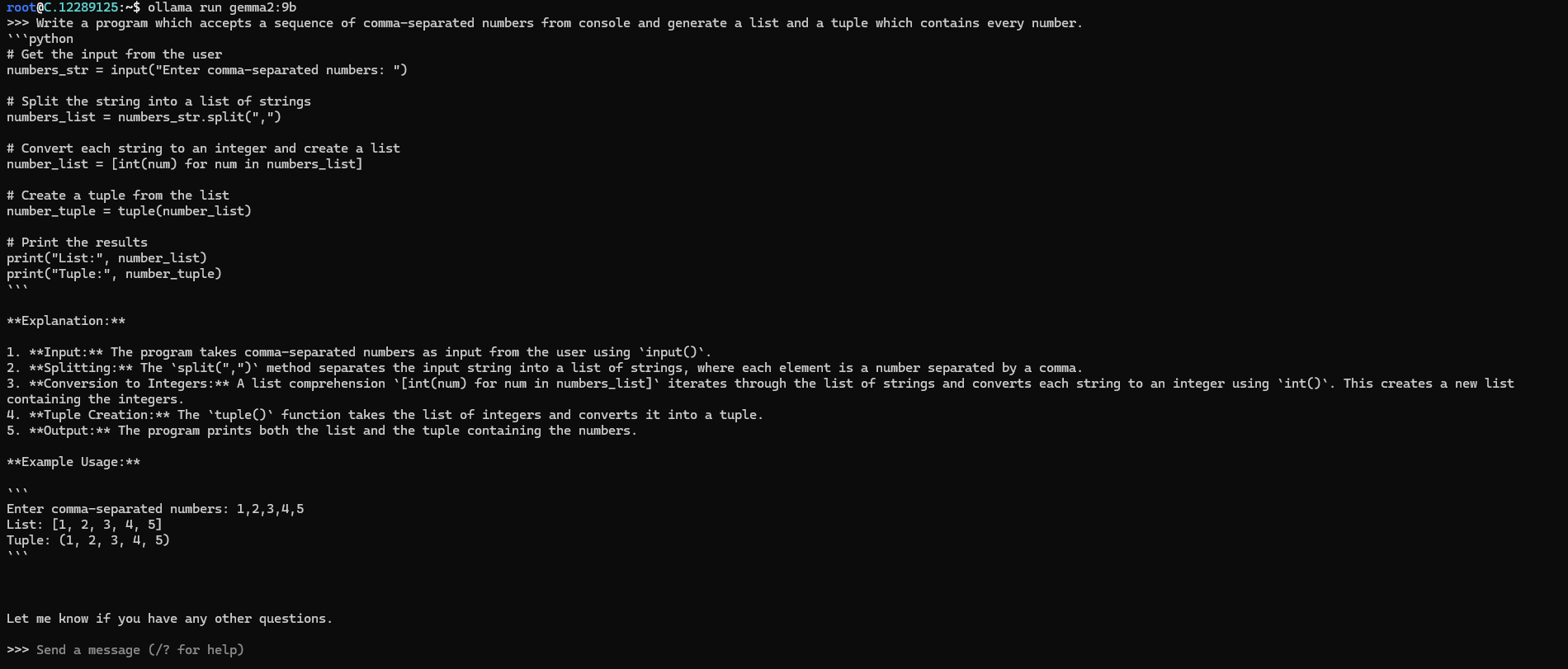
Conclusion
Gemma2 9b is a groundbreaking open-source model from Google that brings state-of-the-art AI capabilities to developers and researchers. Following this step-by-step guide, you can quickly deploy Gemma2 9b on a GPU-powered Virtual Machine with NodeShift, harnessing its full potential. NodeShift provides an accessible, secure, affordable platform to run your AI models efficiently. It is an excellent choice for those experimenting with Gemma and other cutting-edge AI tools.



