How to deploy Llama 3.2 in the Cloud


Llama is a set of large language models trained on 1B and 3B parameters that can process text and images in order to output text. Meta AI has announced the release of Llama 3.2, which introduces the first multimodal models in the series. Llama 3.2 focuses on two key areas:
- Vision-enabled LLMs: The 11B and 90B parameter multimodal models can now process and understand text and images.
- Lightweight LLMs for edge and mobile: The 1B and 3B parameter models are designed to be lightweight and efficient, allowing them to run locally on edge services.
Llama 3.2
The lightweight 1B and 3B models are highly capable of multilingual text generation and tool-calling abilities. These models empower developers to build personalized, on-device agentic applications with strong privacy where data never leaves the device. For example, such an application could help summarize the last ten messages received, extract action items, and leverage tool calling to directly send calendar invites for follow-up meetings.
Running these models locally comes with two significant advantages. First, prompts and responses can feel instantaneous since processing is done locally. Second, running models locally maintains privacy by not sending data such as messages and calendar information to the cloud, making the overall application more private.
| Training Data | Params | Input modalities | Output modalities | Context Length | GQA | Shared Embeddings | Token count | Knowledge cutoff | |
|---|---|---|---|---|---|---|---|---|---|
| Llama 3.2 (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 128k | Yes | Yes | Up to 9T tokens | December 2023 |
| 3B (3.21B) | Multilingual Text | Multilingual Text and code |
Supported Languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported. Llama 3.2 has been trained on a broader collection of languages than these 8 supported languages. Developers may fine-tune Llama 3.2 models for languages beyond these supported languages, provided they comply with the Llama 3.2 Community License and the Acceptable Use Policy. Developers are always expected to ensure that their deployments, including those that involve additional languages, are completed safely and responsibly.
Step-by-Step Process to Deploy Llama 3.2 Model in the Cloud
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meets GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you've signed up, log into your account.
Follow the account setup process and provide the necessary details and information.
Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift's GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.
Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deployment.
Step 3: Select a Model, Region, and Storage
In the "GPU Nodes" tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.
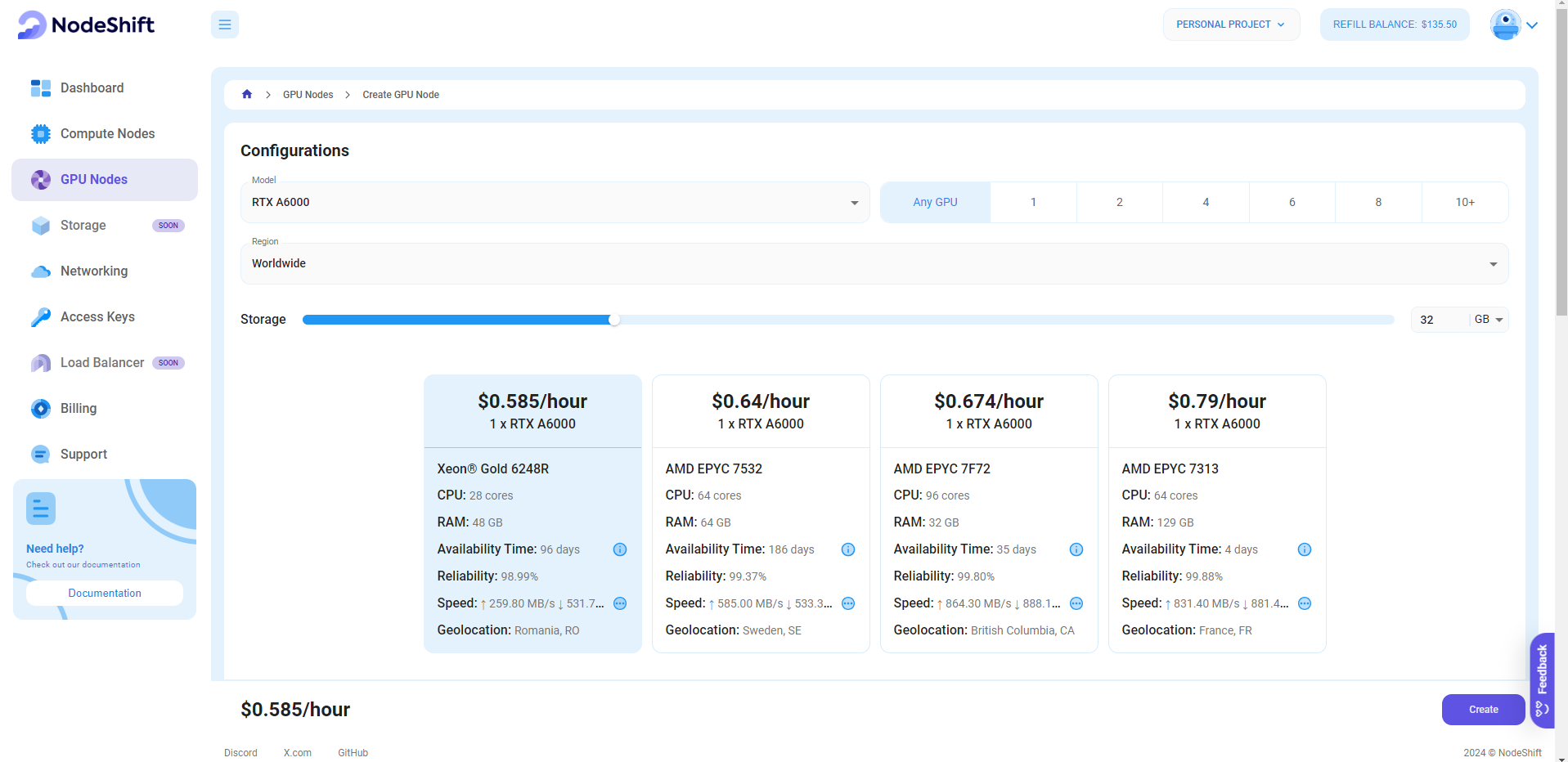
We will use 1x RTX A6000 GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy Llama 3.2 1B on an NVIDIA Cuda Virtual Machine. This proprietary, closed-source parallel computing platform will allow you to install Llama 3.2 1B on your GPU Node.
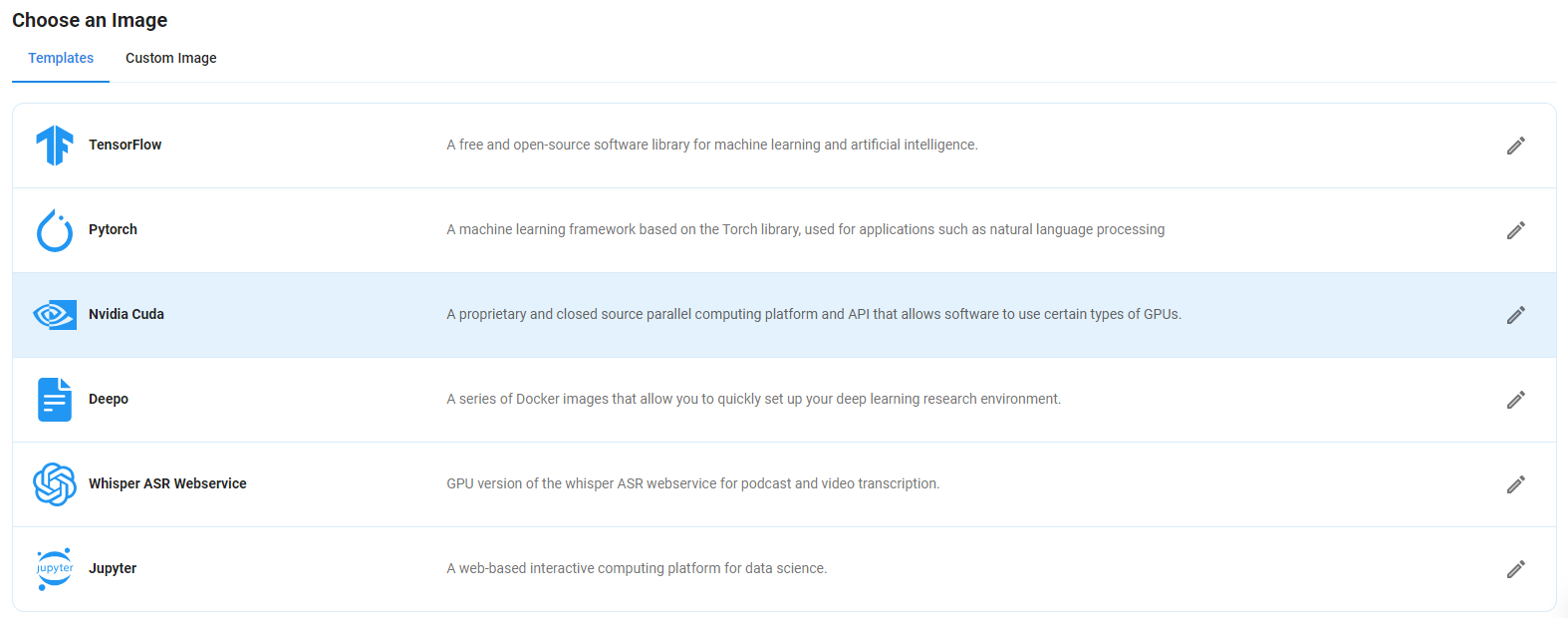
After choosing the image, click the 'Create' button, and your Virtual Machine will be deployed.
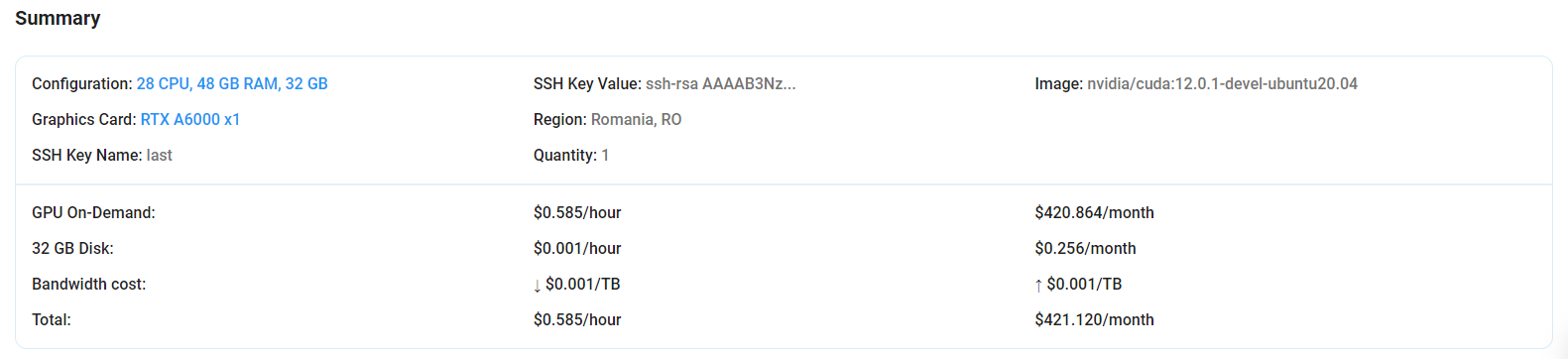
Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.
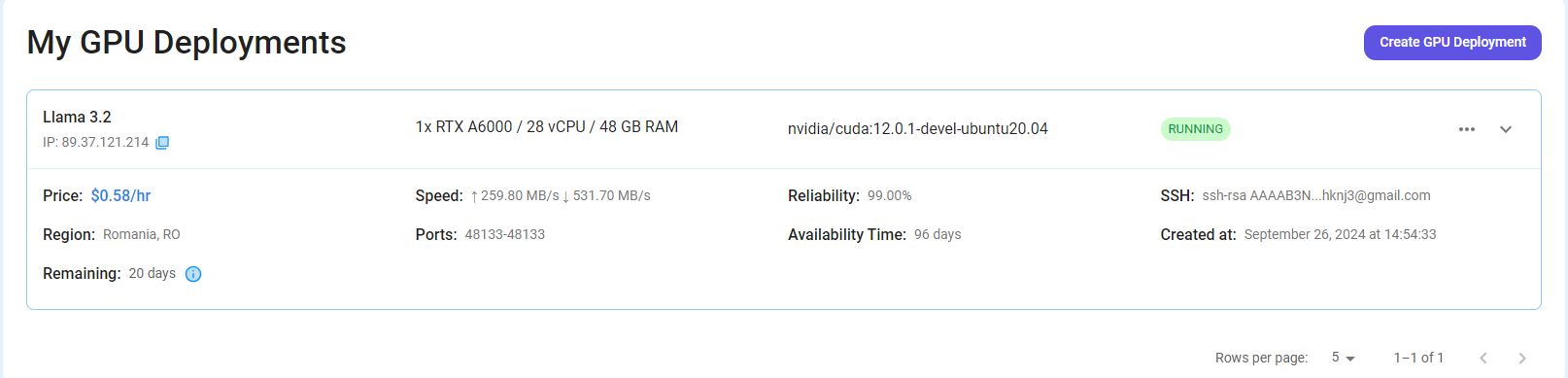
Step 7: Connect to GPUs using SSH
NodeShift GPUs can be connected to and controlled through a terminal using the SSH key provided during GPU creation.
Once your GPU Node deployment is successfully created and has reached the 'RUNNING' status, you can navigate to the page of your GPU Deployment Instance. Then, click the 'Connect' button in the top right corner.
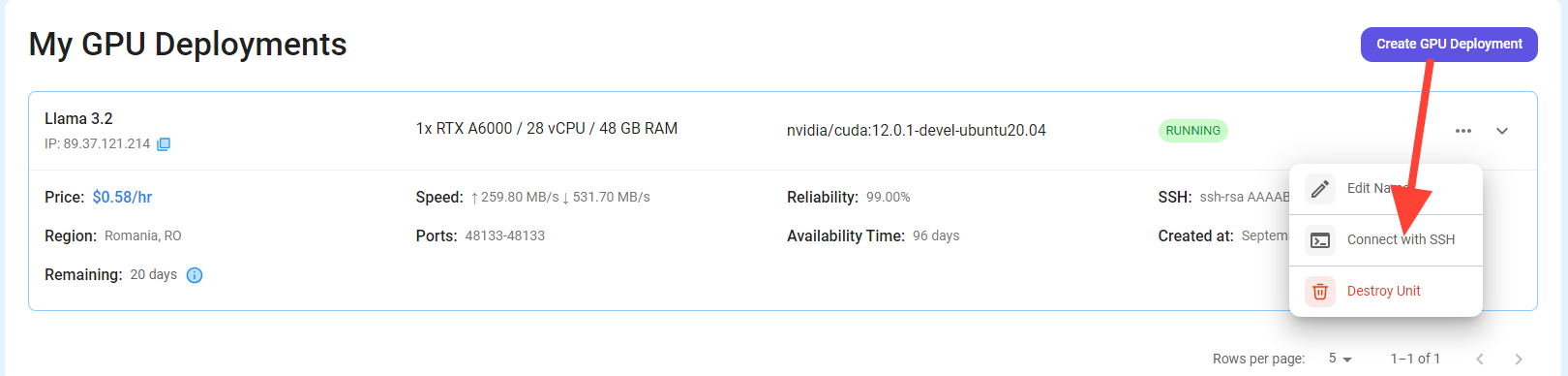
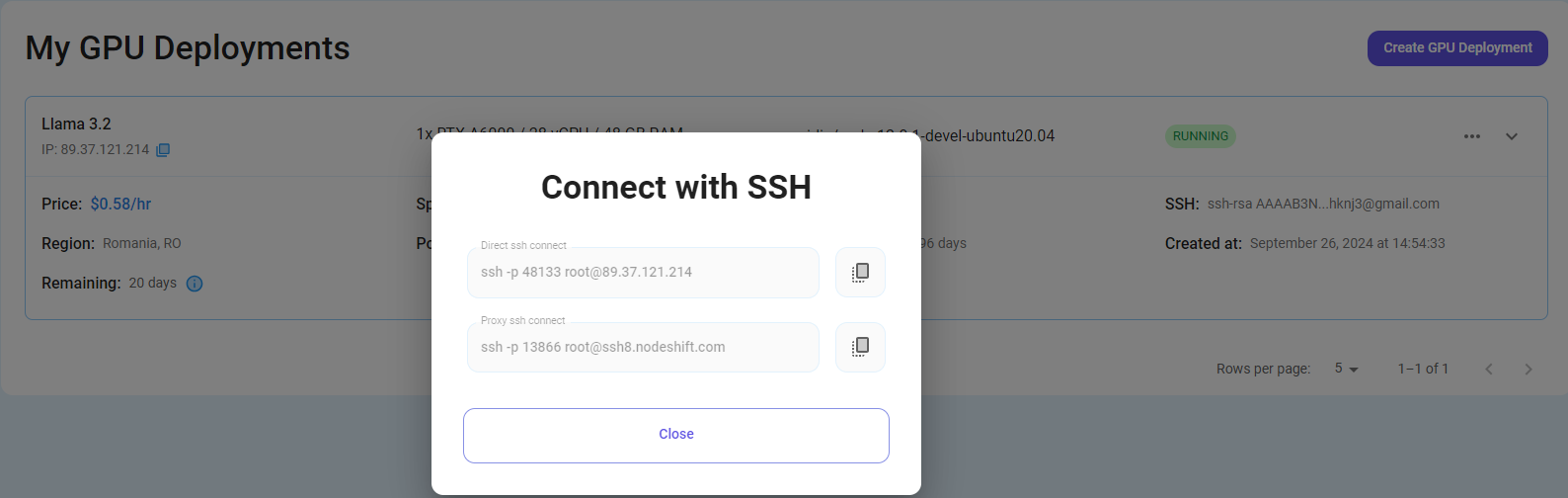
Now open your terminal and paste the proxy SSH IP or direct SSH IP.
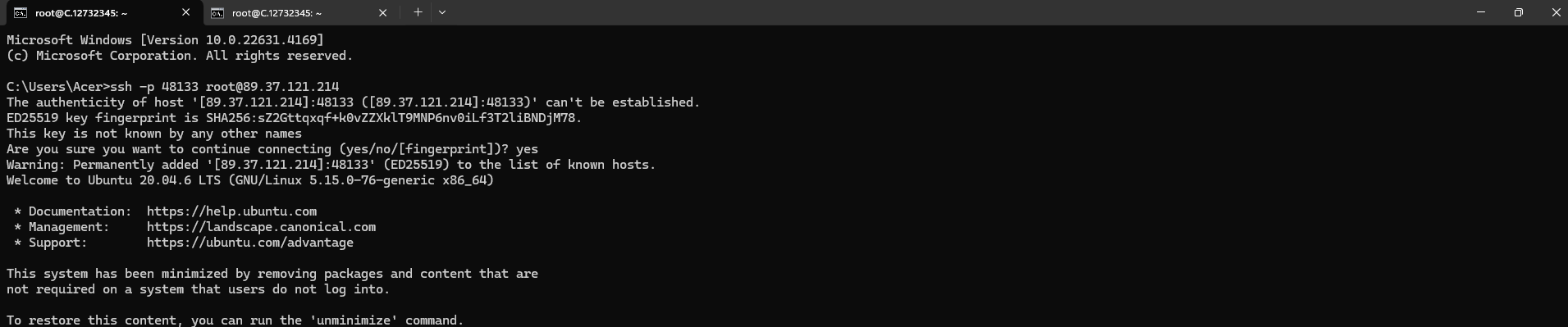
Next, if you want to check the GPU details, run the command below:
nvidia-smi
Step 8: Install Llama 3.2 1B
After completing the steps above, it's time to download Llama 3.2 from the Ollama website.
Website Link: https://ollama.com/library/llama3.2:1b
We will be running Llama 3.2 1B. Select the 1B model from the website.
Then run the following command to install the Ollama:
curl -fsSL https://ollama.com/install.sh | sh
After the installation process is complete, run the following command to see a list of available commands:
ollama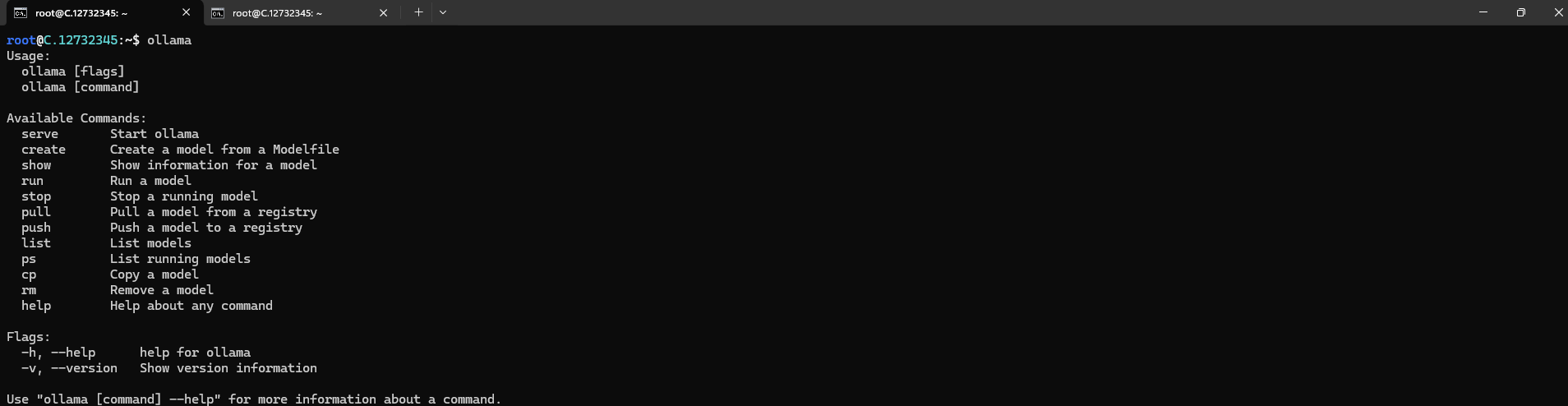
Next, run the following command to host the Llama 3.2 model so that it can be accessed and utilized efficiently.
ollama serve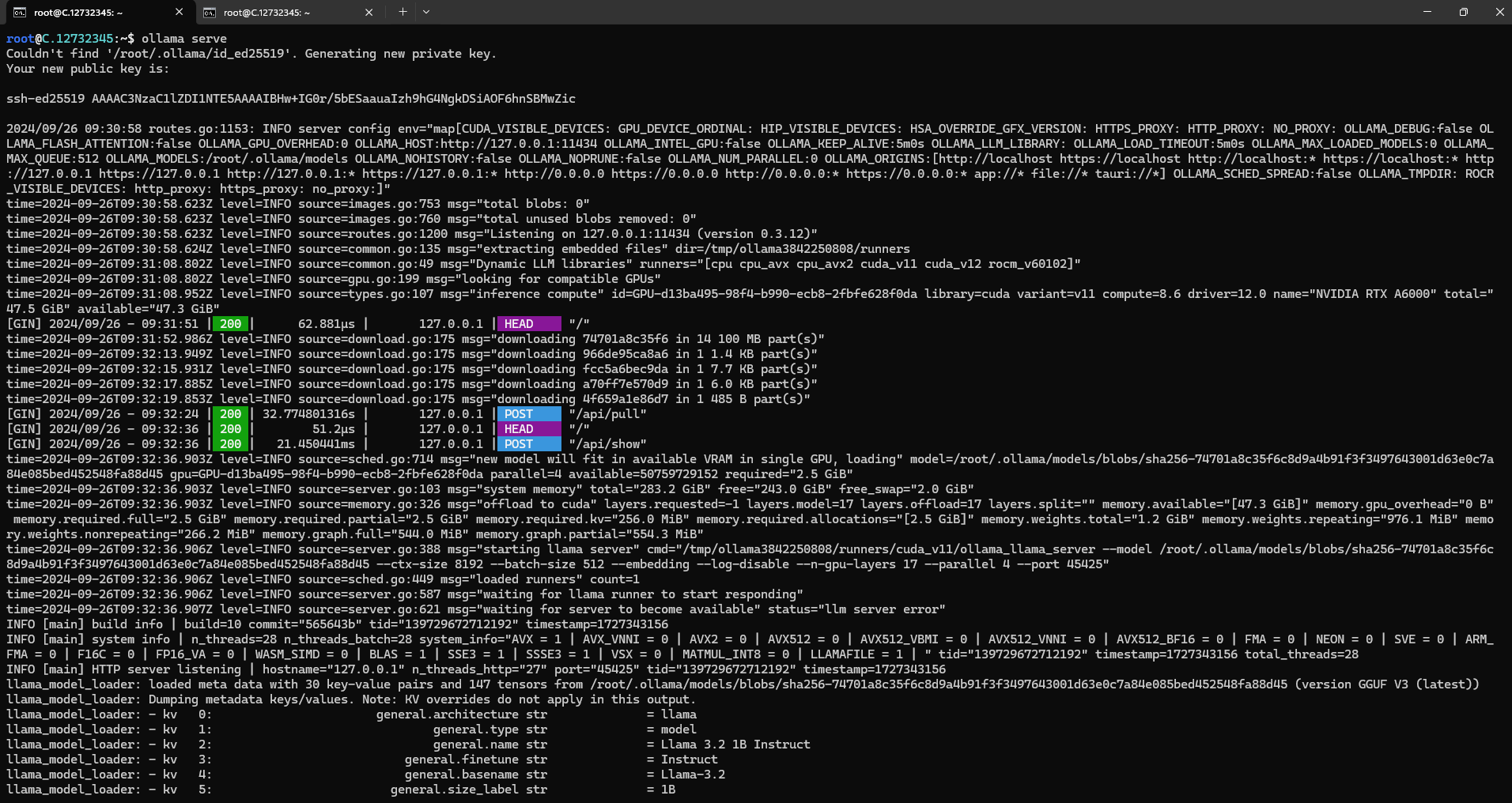
Step 9: Install Llama 3.2 1B Model
To install the Llama 3.2 1B Model, run the following command:
ollama pull llama3.2:1b
Step 10: Run Llama 3.2 1B Model
Now, you can run the model in the terminal using the following command and interact with your model:
ollama run llama3.2:1b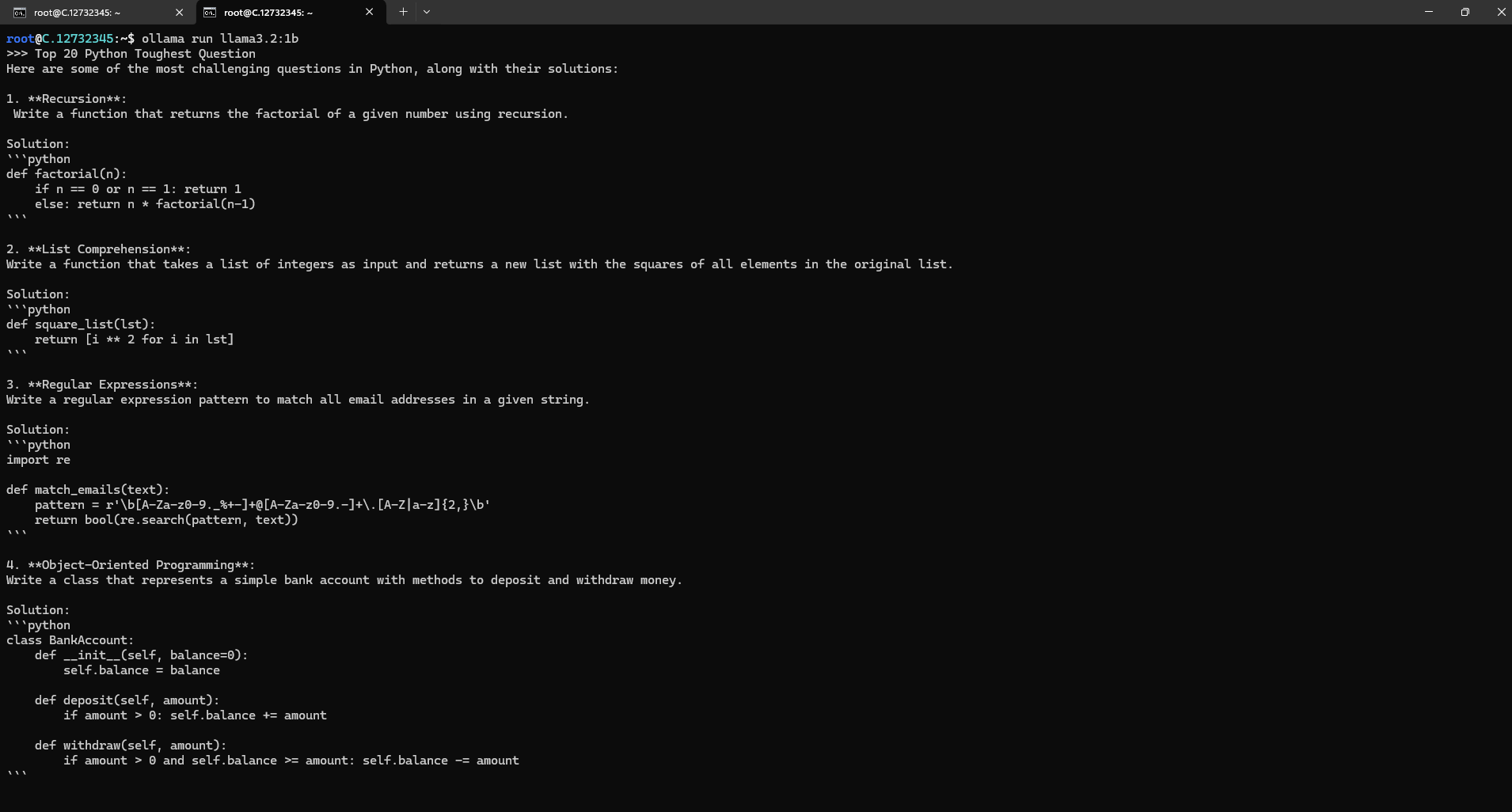
Conclusion
Llama 3.2 1B is a groundbreaking open-source model from Meta that brings state-of-the-art AI capabilities to developers and researchers. Following this step-by-step guide, you can quickly deploy Llama 3.2 1B on a GPU-powered Virtual Machine with NodeShift, harnessing its full potential. NodeShift provides an accessible, secure, affordable platform to run your AI models efficiently. It is an excellent choice for those experimenting with Llama 3.2 and other cutting-edge AI tools.



