How to deploy SmolLM2 1.7B on a Virtual Machine in the Cloud with Ollama?


The SmolLM2-1.7B model by HuggingFaceTB marks a significant leap forward from its earlier version, SmolLM1-1.7B. With 1.7 billion parameters, this compact model is versatile, capable of handling a wide variety of tasks while maintaining a design light enough to operate directly on personal devices. It was trained on a substantial 11 trillion tokens from a rich blend of data sources like FineWeb-Edu, DCLM, The Stack, and fresh collections in mathematics and programming.
Compared to similar-sized models, such as Llama-1B and Qwen2.5-1.5B, SmolLM2-1.7B consistently outperforms across benchmarks measuring comprehension, factual accuracy, logic, and math. The instruction-tuned variant underwent further refinement through focused training and direct feedback alignment, equipping it to handle tasks like rephrasing text, summarizing, and calling specific functions with precision.
Capabilities
The SmolLM2-1.7B model showcases impressive abilities across a range of language comprehension and text generation tasks. It performs well in understanding and responding to instructions, answering questions that involve reasoning and general knowledge, and tackling challenges related to mathematics and programming. The instruction-tuned variant enhances these skills further, enabling it to handle tasks like summarizing text and executing function-based commands effectively.
Model Inputs and Outputs
Inputs
- Natural language text entries
- Dialogue-style conversational inputs
Outputs
- Generated text replies
- Summarized or rephrased content
- Execution of specified functions based on the input
Limitations
The SmolLM2 models are predominantly skilled at handling English text. While they can generate responses across various subjects, the information they produce might not always be entirely accurate, logically sound, or free from inherent biases in the training data. These models are best utilized as supportive resources rather than authoritative references. It’s recommended that users independently verify critical information and thoughtfully assess any generated content.
Ollama
Ollama is an open-source project designed to provide a robust and user-friendly platform for running large language models on a personal computer. It simplifies the complexities of advanced language models, offering users an accessible and adaptable tool for a personalized experience with powerful technology.
Base Pre-Trained Model
| Metric | SmolLM2-1.7B | Llama-1B | Qwen2.5-1.5B | SmolLM1-1.7B |
|---|---|---|---|---|
| HellaSwag | 68.7 | 61.2 | 66.4 | 62.9 |
| ARC (Average) | 60.5 | 49.2 | 58.5 | 59.9 |
| PIQA | 77.6 | 74.8 | 76.1 | 76.0 |
| MMLU-Pro (MCF) | 19.4 | 11.7 | 13.7 | 10.8 |
| CommonsenseQA | 43.6 | 41.2 | 34.1 | 38.0 |
| TriviaQA | 36.7 | 28.1 | 20.9 | 22.5 |
| Winogrande | 59.4 | 57.8 | 59.3 | 54.7 |
| OpenBookQA | 42.2 | 38.4 | 40.0 | 42.4 |
| GSM8K (5-shot) | 31.0 | 7.2 | 61.3 | 5.5 |
Instruction Model
| Metric | SmolLM2-1.7B-Instruct | Llama-1B-Instruct | Qwen2.5-1.5B-Instruct | SmolLM1-1.7B-Instruct |
|---|---|---|---|---|
| IFEval (Average prompt/inst) | 56.7 | 53.5 | 47.4 | 23.1 |
| MT-Bench | 6.13 | 5.48 | 6.52 | 4.33 |
| OpenRewrite-Eval (micro_avg RougeL) | 44.9 | 39.2 | 46.9 | NaN |
| HellaSwag | 66.1 | 56.1 | 60.9 | 55.5 |
| ARC (Average) | 51.7 | 41.6 | 46.2 | 43.7 |
| PIQA | 74.4 | 72.3 | 73.2 | 71.6 |
| MMLU-Pro (MCF) | 19.3 | 12.7 | 24.2 | 11.7 |
| BBH (3-shot) | 32.2 | 27.6 | 35.3 | 25.7 |
| GSM8K (5-shot) | 48.2 | 26.8 | 42.8 | 4.62 |
Step-by-Step Process to deploy SmolLM2 on a Virtual Machine in the Cloud
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meets GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you've signed up, log into your account.
Follow the account setup process and provide the necessary details and information.
Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift's GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.
Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deployment.
Step 3: Select a Model, Region, and Storage
In the "GPU Nodes" tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.
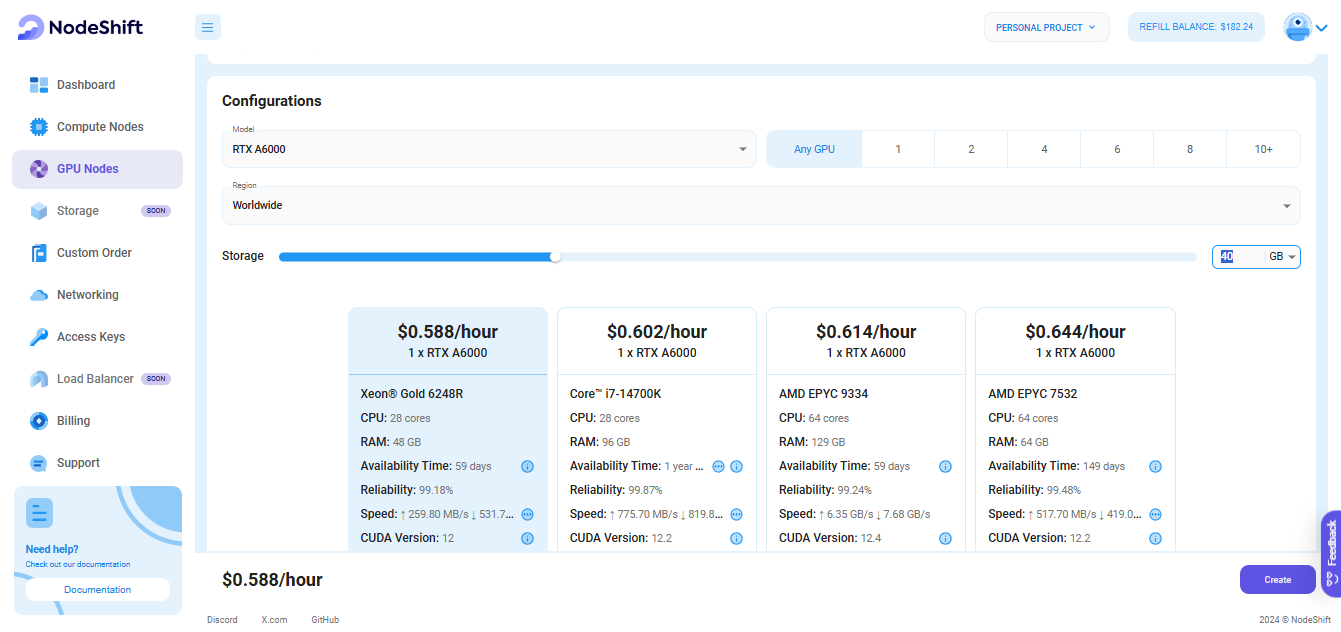
We will use 1x RTX A6000 GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy SmolLM2 on an NVIDIA Cuda Virtual Machine. This proprietary, closed-source parallel computing platform will allow you to install SmolLM2 Model on your GPU Node.
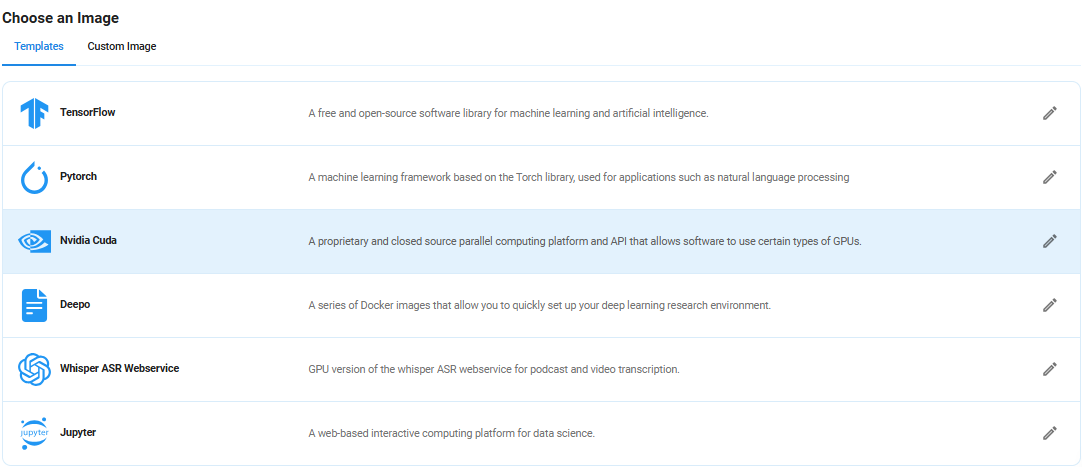
After choosing the image, click the 'Create' button, and your Virtual Machine will be deployed.
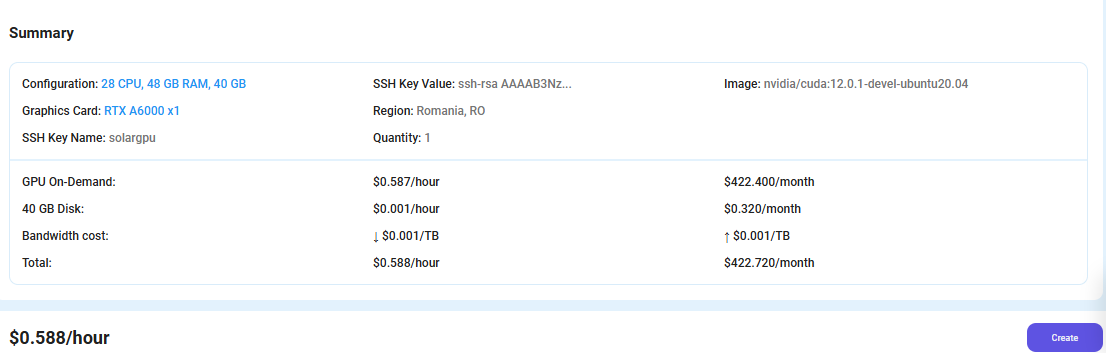
Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.
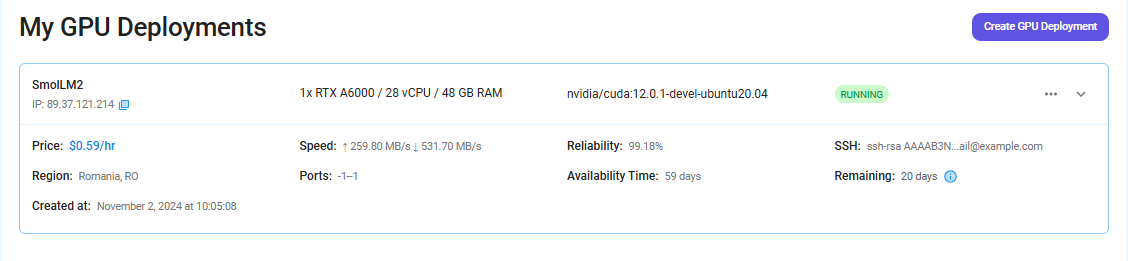
Step 7: Connect to GPUs using SSH
NodeShift GPUs can be connected to and controlled through a terminal using the SSH key provided during GPU creation.
Once your GPU Node deployment is successfully created and has reached the 'RUNNING' status, you can navigate to the page of your GPU Deployment Instance. Then, click the 'Connect' button in the top right corner.
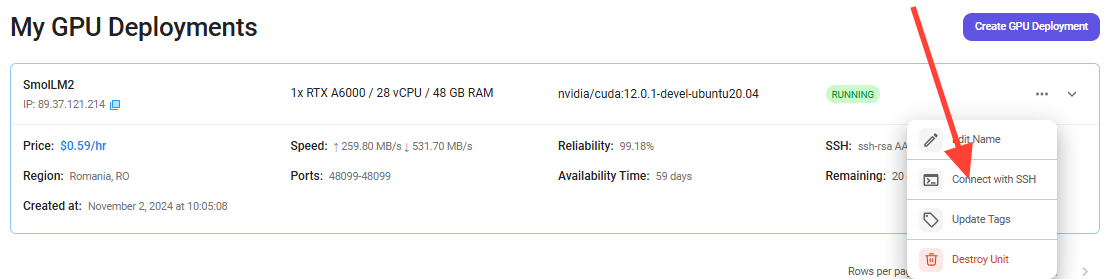
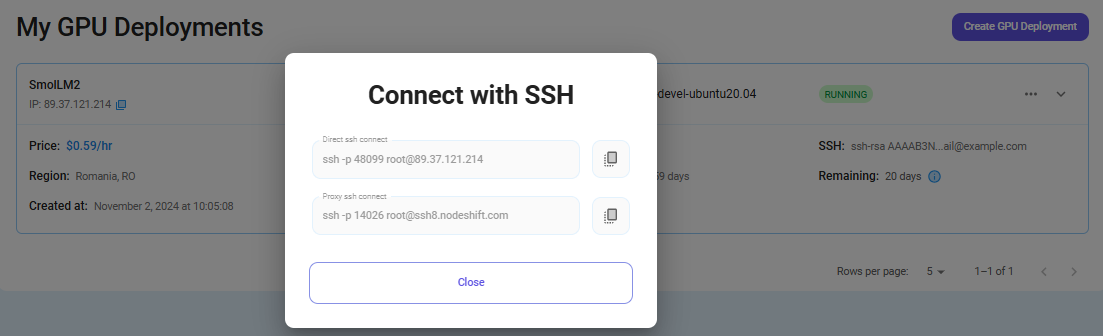
Now open your terminal and paste the proxy SSH IP or direct SSH IP.
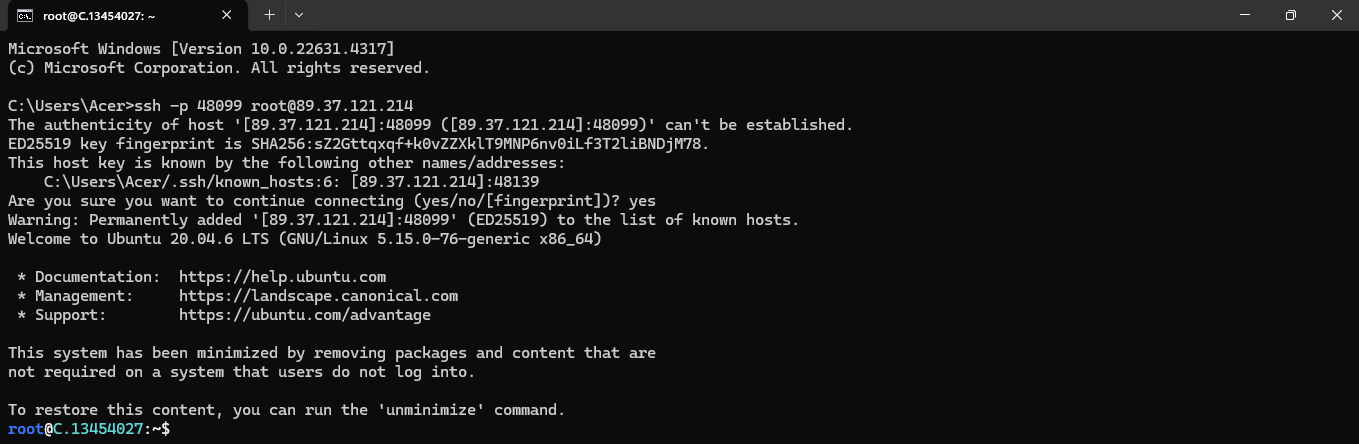
Next, if you want to check the GPU details, run the command below:
nvidia-smi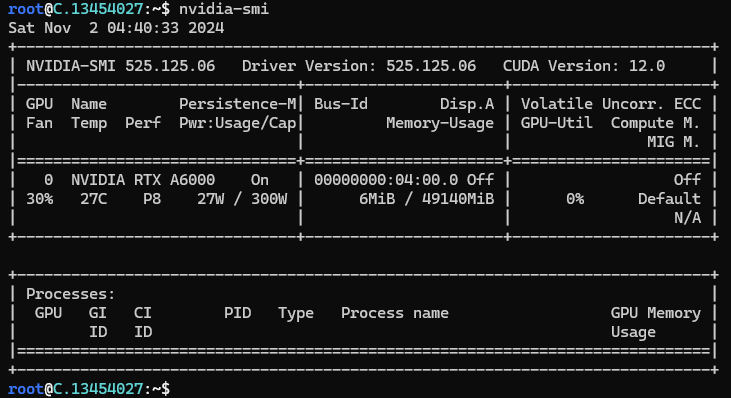
Step 8: Install SmolLM2 1.7B
After completing the steps above, it's time to download SmolLM2 1.7B from the Ollama website.
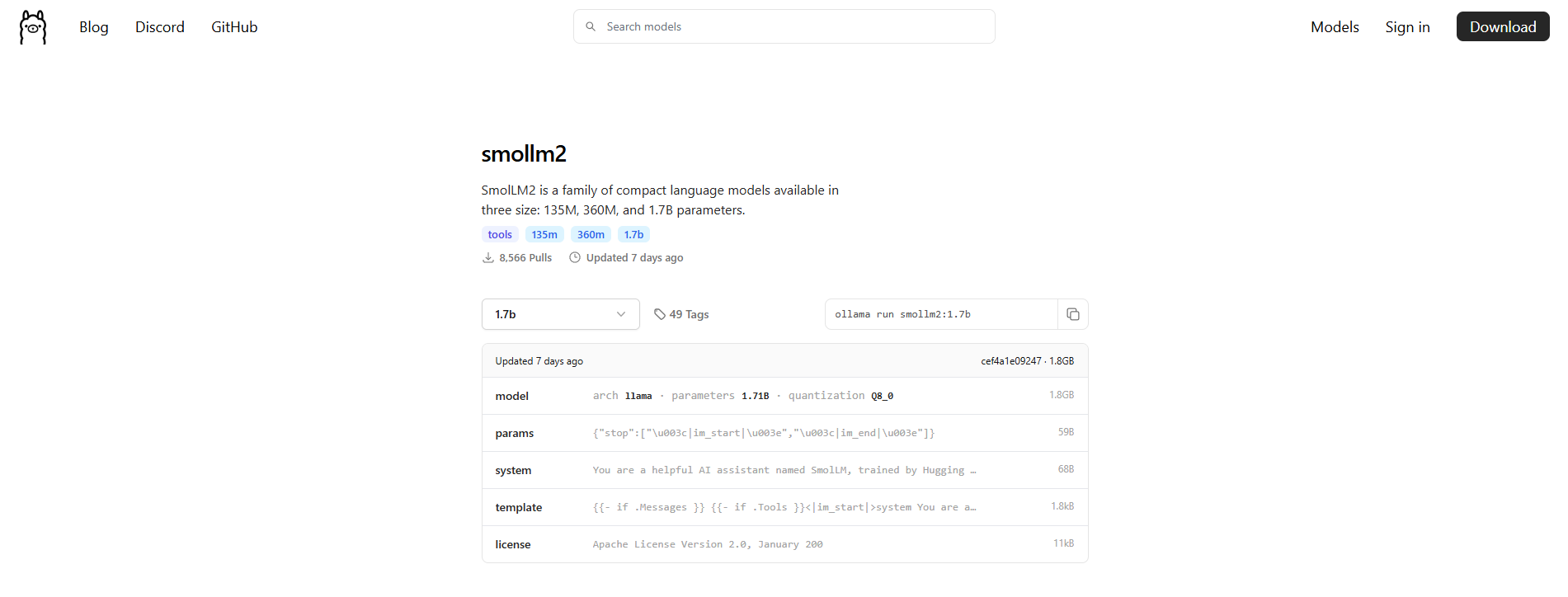
Website Link: https://ollama.com/library/smollm2:1.7b
We will be running SmolLM2 1.7B. Select the 1.7B model from the website.
Then run the following command to install the Ollama:
curl -fsSL https://ollama.com/install.sh | sh
After the installation process is complete, run the following command to see a list of available commands:
ollama
Next, run the following command to host the Llama 3.2 model so that it can be accessed and utilized efficiently.
ollama serve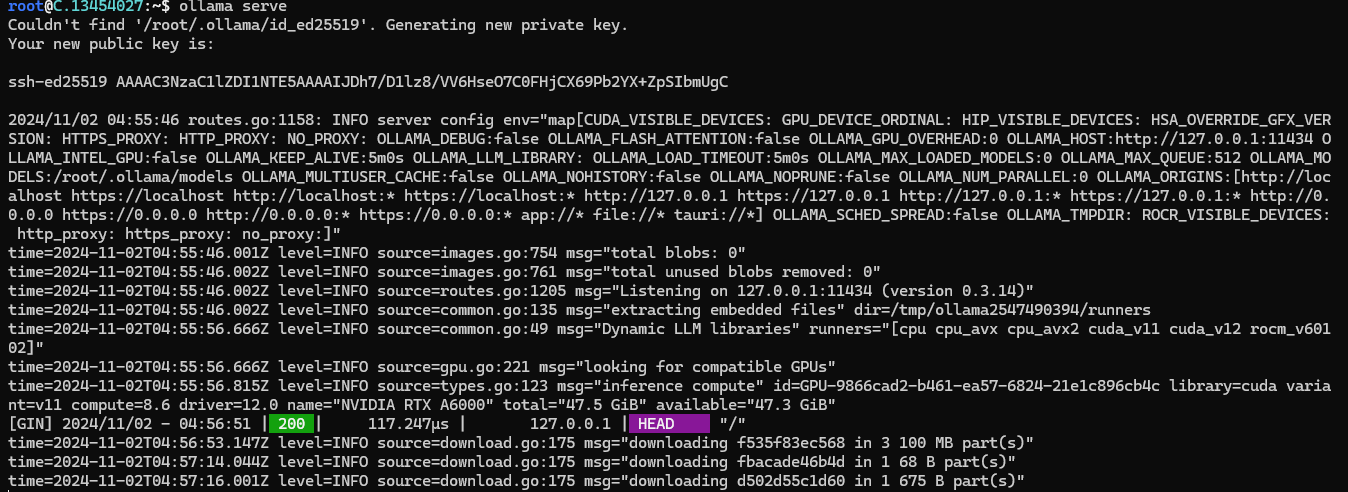
Step 9: Pull SmolLM2 1.7B Model
To pull the SmolLM2 1.7B Model, run the following command:
ollama pull smollm2:1.7b
Step 10: Run SmolLM2 1.7B Model
Now, you can run the model in the terminal using the following command and interact with your model:
ollama run smollm2:1.7b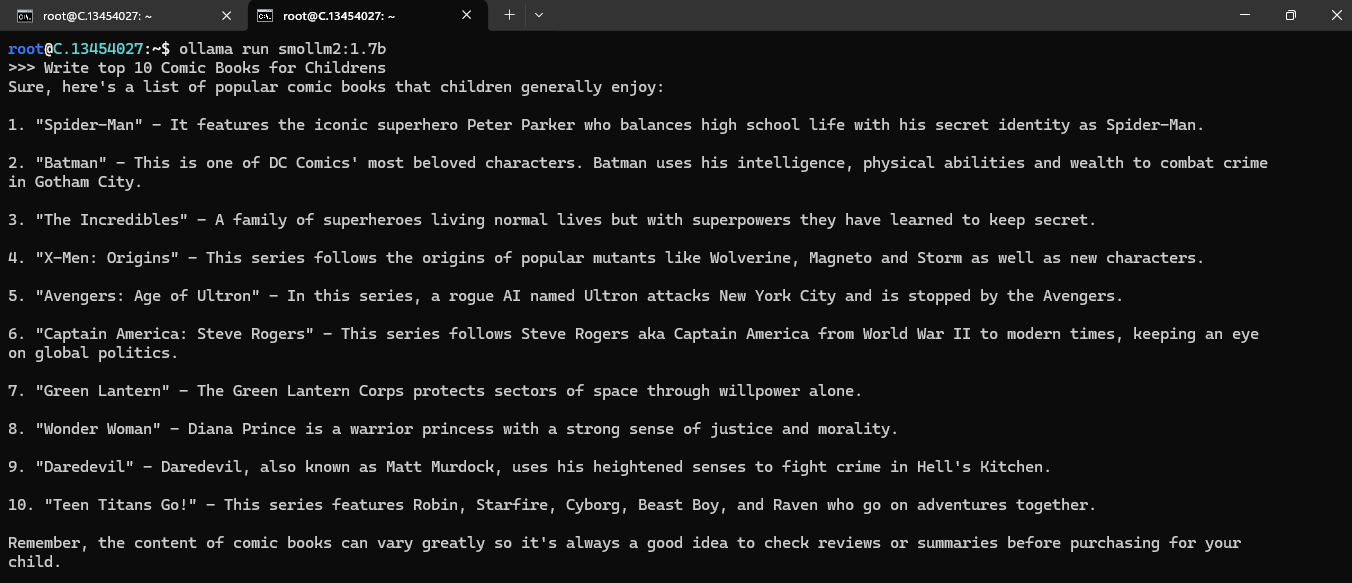
Conclusion
The SmolLM2 1.7B model is a groundbreaking open-source tool from HuggingFace that offers advanced capabilities to developers and researchers. By following this step-by-step guide, you can easily deploy SmolLM2 1.7B on a cloud-based virtual machine with Ollama, using a GPU-powered setup from NodeShift to maximize its potential. NodeShift provides a user-friendly, secure, and cost-effective platform to run your models efficiently. It’s an ideal choice for those exploring SmolLM2 1.7B and other cutting-edge models.



